
The aim of this article is to provide a clear and intuitive inderstanding of the deep learning paradigm known as Neural Architecture Search (NAS).
Table of Contents
The sections of the article are outlined as below:
- Justification for NAS
- NAS: What is it?
- Analogy Time
- NAS Components
- Application of NAS
- Questions
- Resources
- Conclusion
Justification for NAS
From LeNet to Resnet and beyond, the search for new and better neural network paradigms has been a heated activity. This is exacerbated even further by the fact that network design is more of a black art than a science. Which is a roundabout way of saying the designer with the best intuition usually wins!
This has brought up the need for an algorithmic or systematic means of designing networks which follow well-understood principles and are capable of matching human-based network designs, and possibly even improving on them.
Usually, the model design process relies on the designer to make a lot of decisions with regards the hyperparameters. Some of the effort required for this task has been minimized with the use of techniques such as grid search and random search. However, there is still something left to be desired. These techniques tend to deal strictly with hyperparameters that do not affect the network structure e.g. learning rate, batch size, etcetera. They function based on the implicit assumption that the present model architecture is already optimal, which is almost always not true.
This gives rise to the million-dollar question:
What if we could somehow search, not only for the optimal hyperparameters, but also for the optimal architecture?
Rather than designing architecture by hand and algorithmically automate the selection of hyperparameters, is there a way by which we can automate both the architecture design and the hyperparametric selection?
One of the more recent and major answers to this question is Neural Architecture Search.
NAS: What is it?
So, NAS is... We could then go on and give some nebulous definition, but who is that going to help Let us learn by association, connecting the topic of discussion ti=o our everyday experiences.
So without further ado...
Let's go!
Analogy Time
So, let's suppose we have a friend, Mr. X, who is in need of a car. He has just come into a sizeable windfall, and he is of the opinion that its time to get a car.

However, he wants the best possible automobile for the least possible cost. He probably already has some predispositions like: "I hear the Mercedes cars are nice!" or "My friend drives an Audi, and it does quite well".
So, with his mind made up, Mr. X goes to the car dealership, and asks to see the available cars. Obviously, since he already has an inkling of what might be a good fit, he will probably start his search for his desired car amongst the Mercedes or Audi brands, as the case may be.
However, since he is purchasing the car at a large, popular dealership, with lots of cars, he has to be intentional about his purchase attempt. As he has to test drive the cars, there is the imlication that it would be more expedient to find the best car as fast as possible. This would save both Mr. X and the salesman a lot of time and effort. Doing this would require him to be smart about his search, and go about it with some method to the madness, even if something as simple as:
"Pick one car, try it. Is it good enough? No... How about this one?"
We can however take solace in the fact that Mr. X has already taken a first step in this direction by starting his search in the Mercedes and/or Audi section, since he already has some probablilistic assurance that these cars perform adequately.
Having said that, it is very unlikely that he'll find the ideal vehicle at first try. So he would have to test drive it and observe its performance. Based on his observations, he can decide on whether to take the car or to select some other car for more try-outs. If he does go back for re-selection, he would still have to keep his strategy for selection in mind.
He keeps at this over and over, until he finally finds a car he likes.
Mission Accomplished! Perfecto!
NAS Components
With the analogy out of the way, we have to deal with th expected question: how do we relate the analogy to NAS?
Yes well, first of all no one, least of all Mr. X, goes into a car store without at least, some idea of what they are looking for. The idea might be neither clear nor fully-fleshed out, but it is there. The goal of the idea is to provide a starting point, not a final answer. If the answer was already there, we would not be searching now, would we? The search process, if done properly, will allow Mr. X to narrow down his choices. Which is a perfect segue into the second point.
The aforementioned second point is this: There was a laundry list of cars which belong to the Audi or Mercedes brands, and searching through them all would take too much time and effort. This required Mr. X to be a bit judicious with respect to how he went about selecting prospective cars.
Third, the fact that a prospective car seems to be a good prospect does not necessarily make it one. As such, to avoid being inadvertently shortchanged, Mr. X would have had to resist the thought of taking any car at face value. It might just have been a wrong car for him. So, Mr. X had to find a way of testing the car's performance, in this instance, by test driving it.
Finally, based on the observed performance of the prospective car, Mr. X had to make a decision:
(a). Select the car as his choice, or
(b). Go back to searching for his ideal vehicle.
Now that we have explored the analogy, we are in much better stead to understand the NAS process.
The NAS process, according to Elsken et al., 2019, can be summarized via three major components:
(a). The Search Space,
(b). The Search Algorithm/Strategy, and
(c). The Evaluation Strategy.
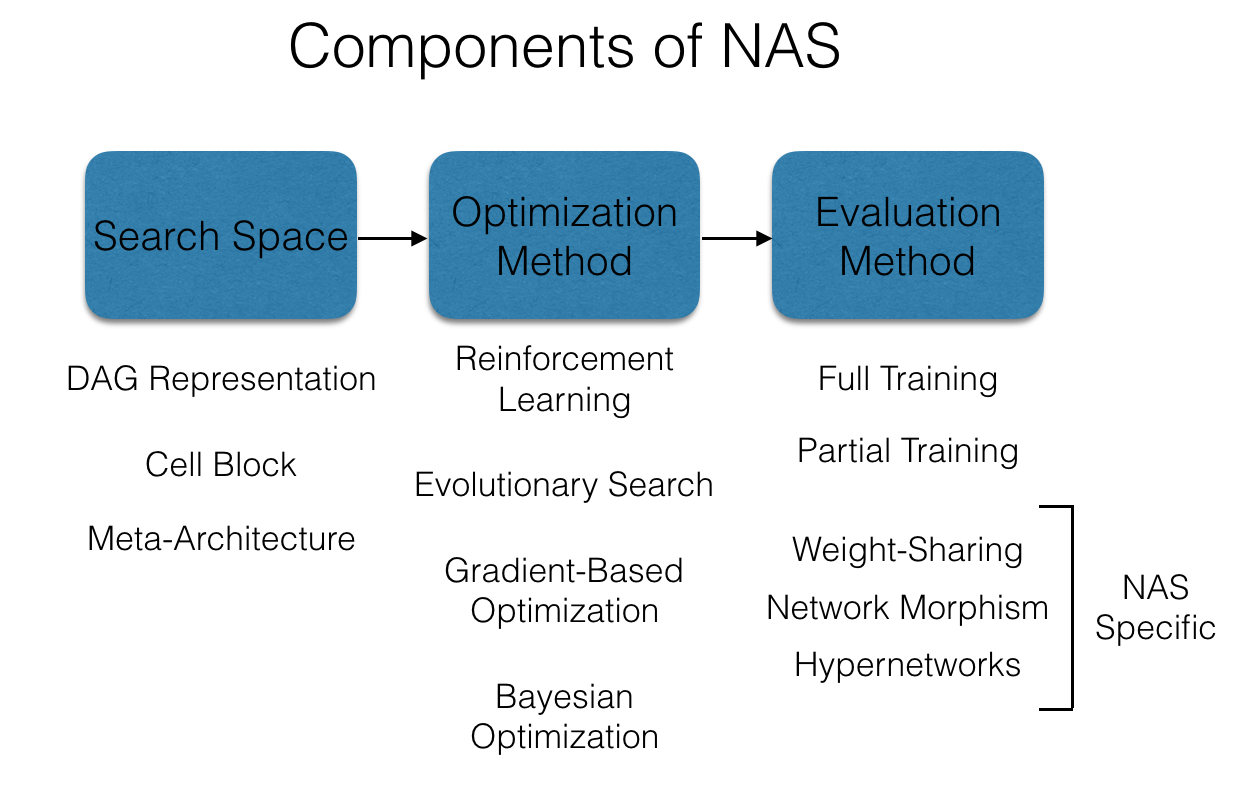
The Search Space is an answer to the points raised first and second previously. It is the set of operations and/or architectural options from which a potential solution would be selected and/or designed. Think of it as akin to the hypothesis space for ML models.

Another way of looking at it is as the initialized weights of a network. We wish to learn the optimal weights for the network, but to do that, we have to start from somewhere. The search space is thse ground zero from where, and within which we begin our search for the ultimate network architecture. Just like with initialized weights, the more correct the "starting point", the faster the search is complete, and the more likely we are to acheive a successful search.
As an example, to develop the optimal architecture for a machine vision problem, we would populate the search space as a set of convolution operations, maybe some transformers and attention modules, to enhance image understanding.
It is for this reason that the search space is usually selected via human expertise and intuition. On the one side of it, this increases the likelihood of bias introduction. On the other, it allows us to take advantage of our real world knowledge and understanding when searching for optimal architectural solutions.
Similar to the automotive population within a car dealership, there are many different means of combining the operations contained in the search space, potentially an infinite number, in fact. There is usually not enough time to exhaustively search all the possible candidates and combinations, as the complexity would be linear in nature (i.e. $O(n)$, where $n$ is the number of trials). This would consume too much effort, and take too much time, without any guarntee of finding s solution.
We need an answer to this issue, and the answer comes in form of a Search Strategy or Algorithm. This is the means by which we intelligently attempt to select our desired (optimal) architecture from the set of possible candidates. Utilizing the search algorithm prior selected, we are able to select candidate architectures, and based on the feedback, intelligently learns to optimize for better architecture selection.
There are a number of choices for search algorithms. They include:
(a). Random Search (naive; depends too much on well-designed search space),
(b). Evolutionary Algorithms (a subset of Genetic Algorithms),
(c). Reinforcement Learning (RL),
(c). and good old Gradient Descent (one-shot learning for architecture design and weights).
Enough said about that.
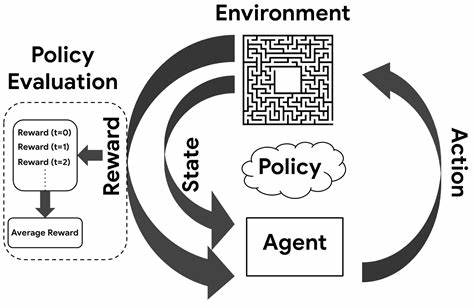
As said previously, the search algorithm learns to intelligently optimize for architecture selection. This implies that the algorithm is learning something. The algorithm must be observing some sort of learning signal that allows it to improve its architecture selection ability over time. This is the only way we can improve our search process, without leaving the propensity for our success completely in the hands of chance. This is an important requirement raised by the fourth point observed previously.
In the NAS framework, this learning signal is provided by an evaluation of the algorithm performance, and this evaluation is provided by the Evaluation Strategy. In order for the search algorithm to improve its searching ability and effectively narrow down the search space, it needs to learn what may make one architecure a better candidate than another, and it also needs to do so (ideally) without explicitly building the model architecture. Since this ideal cannot always be achieved, it will usually suffice that the algorithm is able to observe the architecture performance without spending much time and computation in the process. This is the essence of the evaluation strategy.
The performance of the candidate algorithm is measured as a function of concerns like:
(a). Model size,
(b). Accuracy,
(c). Latency, etcetera.
A number of approaches to evaluate architecture candidates include:
(a). Training from scratch (compute and time intensive!),
(b). Parameter sharing (utilize sets of constant parameters across candidates; reduce evaluation time),
(c). Evaluation on related alternative tasks; usually simpler task.
Applications of NAS
As can be inferred by the discussion earlier, the NAS process lends itself not only to discovering imporved network architectures, but also to selecting good model parameters. This process is known as the one-shot search approach.
However, another promising arena for NAS application is in the field of science. The systematic and algorithmic combination process carried out via NAS might just lend itself to use in other scientific endeavours such as:
(a). Research into genetic modulation and manipulation e.g. DNA research,
(b). Structural design and research e.g. nanotech, amongst others.
We live in interesting times, and it would be a pleasure to see what uses the priciples of NAS will be put to in the nearest future.
Question
Pick the odd one out.
Answer: (c.)
This is the correct answer because the NAS process requires a search space before it starts, and the design of this space requires human expertise.
Resources
Find below a number of videos which might help gain more clarification:
For longer, more detailed treatments of the subject matter, the following should suffice:
Conclusion
With this article at OpenGenus, you must have the complete idea of Neural Architecture Search (NAS).