
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
Data preprocessing is a process of working with the raw data to make it suitable for use with a machine learning model. It is the first and most crucial step while creating a machine learning model. In the context of NLP, it turns the raw text data into a format that ML models can understand by reducing noise and ambiguity in the text data.
Some examples of preprocessing tasks in NLP include:
- Parts-of-speech (POS) tagging
- Stopword removal
- Tokenization
In this article, we shall focus on the concept of stopwords and implementation of stopword removal in NLP.
For this article, we shall be using the Twitter Customer Support dataset available on Kaggle.
Importing the necessary libraries and reading the dataset-
import numpy as np
import pandas as pd
import re
import nltk
full_df = pd.read_csv("../input/customer-support-on-twitter/twcs/twcs.csv", nrows=10)
full_df["text"]=full_df["text"].astype(str)
full_df.head()
Output-

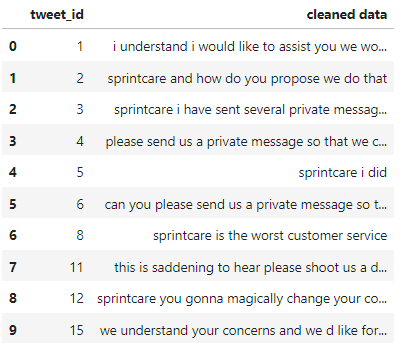
Since the dataset is very large (around 170 mb in size), we shall only be importing the first 10 rows for the purpose of understanding stopwords.
Now as we can see, this dataset contains a lot of unnecessary information. Other than that, there are a few quality issues as well. We’ll be resolving them.
for x in list(full_df.columns):
if x not in ['tweet_id','text']:
del full_df[x]
df=full_df
ps = list(";?.:!,")
#replace certain punctuation marks
for p in ps:
df['text'] = df['text'].str.replace(p, '')
#replace whitespaces
df['text'] = df['text'].str.replace(" ", " ")
#replace quote signs
df['text'] = df['text'].str.replace('"', '')
#replace tab spaces
df['text'] = df['text'].apply(lambda x: x.replace('\t', ' '))
#replace apostrophe s
df['text'] = df['text'].str.replace("'s", "")
#replace newline symbol
df['text'] = df['text'].apply(lambda x: x.replace('\n', ' '))
#make text lowercase
df['text'] = df['text'].apply(lambda x:x.lower())
#data cleaning using regular expressions
def cleandata(txt):
txt = re.sub('[^a-zA-Z]', ' ', txt)
txt = re.sub('http\S+\s*', ' ', txt)
txt = re.sub('RT|cc', ' ', txt)
txt = re.sub('#\S+', '', txt)
txt = re.sub('@\S+', ' ', txt)
txt = re.sub('\s+', ' ', txt)
return txt
df['cleaned data'] = df['text'].apply(lambda x: cleandata(x))
del df['text']
df
Output-
Moving forward, we shall be creating a bag of words for this dataframe. A bag of words is essentially a collection of all the words used in a dataset, where their order is ignored but their frequencies are stored.
from sklearn.feature_extraction.text import CountVectorizer
CountVec = CountVectorizer(ngram_range=(1,1),
stop_words=None)
#transform
Count_data = CountVec.fit_transform(df['cleaned data'])
#create dataframe
cv_dataframe=pd.DataFrame(Count_data.toarray(),columns=CountVec.get_feature_names())
cv_dataframe
Output-
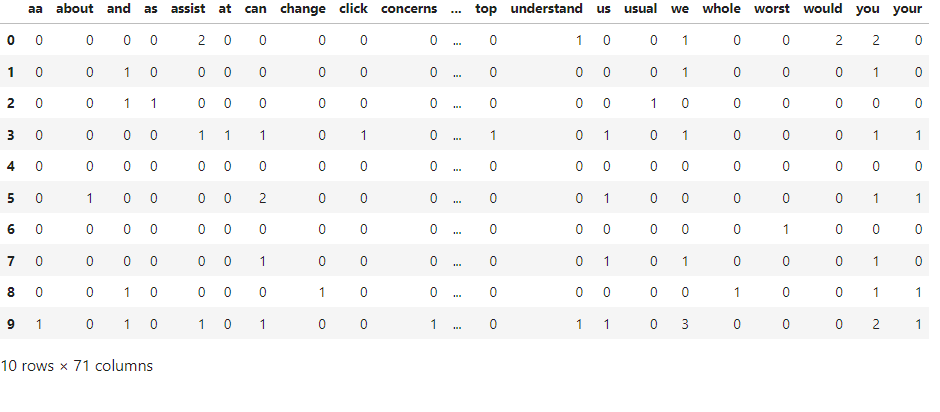
The Bag of Words model is useful is many NLP tasks such as text classification, sentiment analysis, and information retrieval, but processing a large bag of words can be computationally expensive as well as cause problems in insight generation, as many uninsightful words may be present which don’t provide any value to the model but take up a lot of space. An example can be seen in this bag of words where a lot of words like ‘about’, ‘and’, ‘can’, ‘you’ etc are present which are commonly used in a language but do not carry much meaning or significance. Such words are called stop words in the context of NLP tasks.
What are Stop Words?
Stop words are commonly used in a language but do not carry much meaning or significance. They are often used to connect other words or to form grammatical structures. These words are so common that they appear in almost every text and are unlikely to provide any insights or valuable information to the analysis of the text.
Types of Stop Words
- Determiners- Words placed before nouns to provide additional information (Eg. articles, possesives, demonstratives, quantifiers etc.)
- Conjunctions- words that join two phrases (Eg. and,or,but etc.)
- Prepositions- Indicate relationships between other words.(Eg. in, at, on,of etc.)
- Pronouns- Replace nouns in a sentence (Eg. He, She, They)
- Auxillary Verbs- A verb used wih another verb to indicate tenses. (Eg. am, be, have etc)
List of Stop Words
This link provides a list of all stop words in the English language that are recognised by the NLTK library.
Stop Words- To remove or not to remove?
Now, the question remains that since they are unlikely to provide any insight and only take up space, shouldn’t they be removed?
Well, yes and no. While it is true that in many NLP applications, removing stopwords can improve the accuracy and efficiency of text analysis as they can create noise in the data and make it more difficult to extract useful information, it is also true that stopwords are necessary to maintain the structure of the data and any task involving analysis of language structure/ language generation etc where the structure of the data is to be maintained requires retention of stopwords. In situations where the structure of the data is not as important eg. information retrieval, stopwords may be removed.
Below is an overview of situations where stopwords may or may not be removed.
| May Remove Stopwords | May Not Remove Stopwords | |
|---|---|---|
| Document Classification | Language Generation | |
| Information Retrieval | Short Text Analysis | |
| Machine Translation | When Rule Based Algorithms are involved | |
However, it needs to be understood that whether stopwords should be or should not be removed can't be decided 100% based on the category of the task. There may be certain cases which fall into either of the two categories, an example being sentiment analysis. Although stopwords can be removed here to improve the accuracy of the classification model, the absence or presence of words like "not" or "but" - which are stopwords, can play a crucial role in determining the sentiment of the text.
Essentially, the choice of whether to delete or retain stopwords in NLP relies on the particular task, the kind and size of the text data, and the domain of the data. It is necessary to take into account the potential influence of removal of stopwords on the analysis and take appropriate informed decisions which suit the task at hand.
Stopword Removal
For the purpose of this guide, let's assume that stopwords need to be removed. To remove them, we shall be tokenising the words and matching them with an inbuilt list of stopwords. Any matching stopwords shall be removed from the matrix.
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
def remove_stopwords(text):
stop_words = set(stopwords.words('english'))
tokens = word_tokenize(text)
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
filtered_text = ' '.join(filtered_tokens)
return filtered_text
df['filtered text'] = df['cleaned data'].apply(remove_stopwords)
del df['cleaned data']
df
Output-
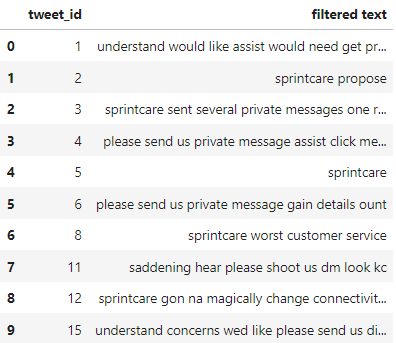
Now we shall be creating another bag of words to compare the results, before and after stopword removal.
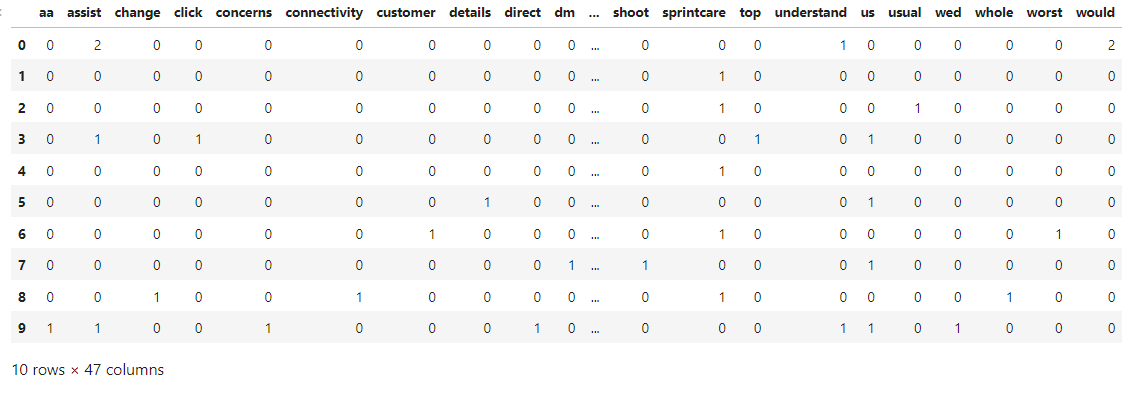
Comparing the two matrices, it is evident that this matrix, having 47 columns and 10 rows is much smaller compared to the initial matrix which had 71 columns and 10 rows.
Conclusion
To conclude, stopword removal can hold immense value in reduction of noise as well as less required storage and consequently, less computational cost upon iteration. However, the decision of removing or not removing stopwords depends upon the nature and the goal of the task at hand.
Question to ponder upon
Q1) Do stopwords inherently have no use?
Q2)Should stopwords be removed or not removed for sentiment analysis tasks?
References -