
In this article, we will learn about the fundamentals of Text Summarization, some of the different ways in which we can summarize text, Transformers, the BART model, and finally, we will practically implement some of these concepts by working with a functioning model (in Python) in order to understand how we can shorten a block of text while retaining all of the important information that it conveys.
Text Summarization
Text Summarization is essentially the process of shortening a long piece of text (such as an article or an essay) into a summary that conveys the overarching meaning of the text by retaining key information and leaving out the bits that are not important. There are two broad methods that we employ when we summarize text:
- Extractive Summarization
- Abstractive Summarization
Extractive Summarization
In Extractive Summarization, we generate a summary by extracting specific lines of text from the original block of text, without altering this text in any way. Thus, all of the lines of text in the summary are already present in the original block of text. The model simply extracts the lines of text that it finds to be important, but does not generate anything that does not already exist in the original block of text. Most summarization systems happen to be extractive.
Abstractive Summarization
In Abstractive Summarization, we generate a summary by building an internal semantic representation of the original block of text, and then using this representation to generate an entirely new block of text. This new block of text (the summary) contains sentences that are different from the ones in the original block of text, which is similar to the way humans rephrase and shorten excessively long blocks of text. Abstractive methods are generally far more computationally expensive than extractive methods, since we need to generate grammatically and contextually intact sentences that are relevant to the domain that is being referred to. The model has to first thoroughly understand the original block of text in order for it to be able to summarize it effectively and meaningfully.
Now that we have a solid understanding of Text Summarization as well as the two general methods that we use to summarize text, we are in a position to learn about Transformers and how they are used in Text Summarization.
Transformers
For a long time, recurrent models (such as Recurring Neural Networks, Long Short-Term Memory, etc) have been in use for language modeling and machine translation problems. These models, however, are inherently sequential in nature, and this poses problems when we have to deal with longer sequence lengths, as memory constraints begin to limit batching across examples. Since RNNs process data sequentially (or one data element at a time), it isn't possible to speed them up significantly by simply increasing the amount of processing power. This makes it difficult for us to train RNNs on very large amounts of data. This is because they're slower to train, owing to the reduced scope for parallelization. While we have managed to greatly increase the computational efficiency of such models in recent times, the drawbacks that are associated with sequential computation are still real and detrimental.
This is where Transformers come into the picture. Transformers are a type of neural network architecture, and were developed by a group of researchers at Google (and UoT) in 2017. They avoid using the principle of recurrence, and work entirely on an attention mechanism to draw global dependencies between the input and the output. Transformers allow for much more parallelization than sequential models, and can achieve very high translation quality even after being trained only for short periods of time. They can also be trained on very large amounts of data without as much difficulty. The GPT-3 (Generative Pre-Trained Transformer-3) model, for example, was trained on an exceptionally large amount of data, nearing 45 terabytes!
There are three distinct features about Transformers that make them work so efficiently:
- Positional Encoding
- Attention
- Self-Attention
1. Positional Encoding
Positional Encoding is the idea that instead of looking at a sentence sequentially (or word by word), we take each word and assign it a unique representation.
So if we have a sentence like:
'He likes to eat ice cream.'
Then, each word of the sentence is assigned a specific index as follows:
He -> 1
likes -> 2
to -> 3
eat -> 4
ice -> 5
cream. -> 6
In practice, these words are not assigned simple index values. Transformers use smart positional encoding schemes, where each position is mapped to a vector. Thus, we actually end up with a positional encoding matrix, where we can find positional information as well as the encoded objects of the sentence. For now, however, to understand these concepts better, we will use the above example.
By indexing each word of the sentence, we are storing information about the word order in the data itself, rather than in the structure of the network. Initially, the network will not know how to interpret these positional encodings, but as it works with large amounts of data, it begins to learn how to make use of them. Thus, the network learns about the importance of word order from the data. This makes it easier for us to train Transformers than RNNs.
2. Attention
Suppose we want to translate a sentence from English to Hindi. One primitive way to do so would be to take each word of the English sentence, one by one, and translate it to Hindi. This is not an ideal way to translate a sentence, since the order of words in sentences conveying the same message is often slightly different from language to language.
For example, if we have the sentence:
'Max wants to play.'
The equivalent sentence in Hindi would be:
'मैक्स खेलना चाहता है।'
Here, the Hindi words for 'wants to' and 'play' are shuffled. If we translated the English sentence one word at a time, however, we'd end up with the sentence:
'मैक्स चाहता है खेल।'
This sentence, while still somewhat decipherable, is far from being the correct Hindi representation of the English sentence 'Max wants to play.'
Attention is a mechanism that makes it possible for a model to contextualize each word in a given sentence, which gives it a clearer picture of what the final translated sentence should look like. This is something that the model can learn with the help of training data. By looking at a large number of examples of sentences in both languages, the model can start to learn about the interdependency of words, the different rules of grammar and punctuation, and more such linguistic details.
3. Self-Attention
In the previous section of the article, we talked mostly about text translation, which is a very specific language task. What if instead, we wanted to build a model that could learn about the core fundamentals of a language such that it could perform any number of language tasks? This is what Self-Attention helps us do. Self-Attention makes it possible for a neural network to understand a word in the context of the sentence that it is used in.
For example, in the following sentences:
'He was told to park the car closer to the wall.'
'She went to the park today.'
In these sentences, the word 'park' assumes different meanings. Humans can easily contextualize these words and infer that they mean different things, and this is what Self-Attention allows neural networks to do.
In the first sentence, the model might look at the word 'car' and infer that the word 'park' here means- the parking of a vehicle, whereas in the second sentence, the model might look at the words 'She went' and infer that the word 'park' here means- a playground or a garden.
How Do Transformers Work?
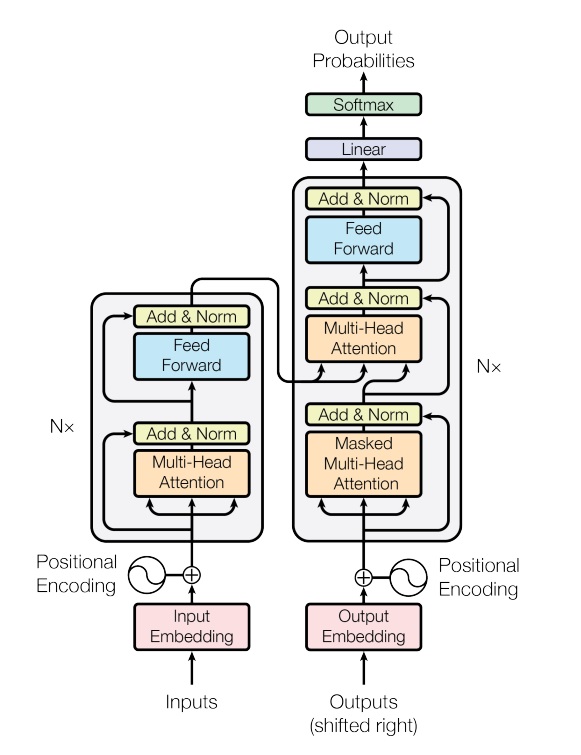
As we can see from the above diagram, Transformers are comprised of a few different sections: an encoder stack and a decoder stack, input and output pre-processing units, and an output post-processing unit. Here, the input sequence is mapped into an abstract continuous representation by the encoder. The decoder then takes this abstract continuous representation and generates an output while being fed the previous output.
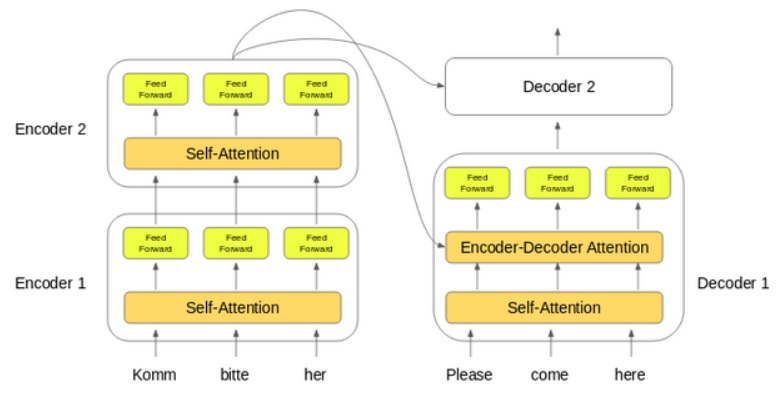
The first encoder receives the word embeddings of the input sequence. Then, these are transformed and sent to the next encoder. Finally, the output from the last encoder in the stack of encoders is passed to the entire stack of decoders.
Before we work with a practical model, let's quickly take a look at the architecture and the uses of a type of Transformer known as BART.
BART
BART, or Bi-Directional Auto Regressive Transformer, is a sequence-to-sequence de-noising auto encoder. A BART model is capable of taking an input text sequence and generating a different output text sequence (for example, an English input -> a French output). These models are commonly used in machine translation, text and sentence classification, as well as text summarization!
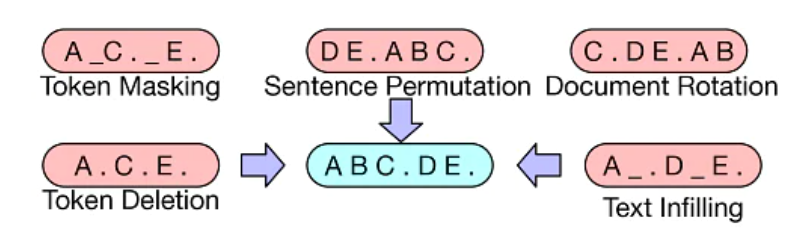
The BART model as proposed in the research paper 'BART: De-noising Sequence-to-Sequence Pre-Training for Natural Language Generation, Translation, and Comprehension', was trained using training data that included noisy (or corrupt) data, which was then mapped to the original data that it was obtained from. The authors of the research paper used multiple novel transformations in order to introduce noise to the data for pre-training. Some of these transformations are as follows:
-
Token Masking: Random tokens in sentences are replaced with [MASK] elements.
-
Token Deletion: Random tokens in the input sequence are deleted. It is up to the model to predict which positions do not have inputs.
-
Text Infilling: A number of tokens are replaced with a singular [MASK] token. It is up to the model to learn about how many tokens are missing as well as the
content of the missing tokens. -
Sentence Permutation: Sentences are randomly rearranged/permuted. This makes it possible for the model to learn the logical sequence of sentences.
-
Document Rotation: A random token is picked, and the document is made to begin with that token. The content before that particular token is added to the end of the document. This makes it possible for the model to identify what the start of the document looks like.
The first part of BART uses the bi-directional encoder of BERT (which is another Transformer model based on bi-directional encoding) to find the ideal representation of the input text sequence.
Once we have this ideal input text sequence representation, we require a decoder to interpret the input text sequence and map it to the output target. To do this, we use the auto regressive decoder of GPT (which is another Transformer model based on auto regressive decoding), which only looks at the past data to make new predictions.
Thus, the BART model looks something like this:
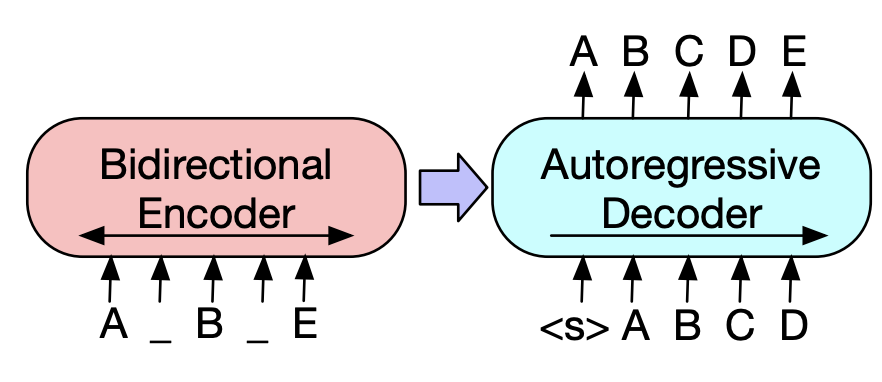
Here, the input sequence is a corrupted version of [ABCDE], transformed into [A[MASK]B[MASK]E]. This corrupted sequence is then encoded with the bi-directional encoder, and the likelihood of the original text, [ABCDE], is calculated by the auto regressive decoder. This model can further be fine tuned by feeding the un-corrupted original text to both the encoder as well as the decoder.
As we discussed earlier, the BART model is a powerful tool in machine translation, text and sentence classification, as well as text summarization. The BART model performs comparably or better than previously proposed models in various tasks.
Now that we have a strong understanding of vanilla Transformers as well as the BART model, we will work with HuggingFace's Transformers (which is a Python library) to learn how these models are used in the real world! We will do so using the pipeline API.
Code
First, we install the required libraries.
pip3 install transformers torch sentencepiece
Then, we import 'pipeline'. We use the pipeline API as it makes it simple for us to make use of the models in 'transformers'.
from transformers import pipeline
Now, we define the text that we wish to summarize. In this case, we are going to summarize an article that talks about the '2021 Formula One World Championship'. This article goes into great detail about all of the events that unfolded over the course of the season, however, we only wish to retain the important bits: that is, which team won the World Constructors' Championship, which driver won the World Driver's Championship, and how many races were held in total.
original_text = """
The 2021 FIA Formula One World Championship was a motor racing championship for Formula One cars which was the 72nd running of the Formula One World Championship. It is recognised by the Fédération Internationale de l'Automobile (FIA), the governing body of international motorsport, as the highest class of competition for open-wheel racing cars. The championship was contested over twenty-two Grands Prix, and held around the world. Drivers and teams competed for the titles of World Drivers' Champion and World Constructors' Champion, respectively.
Max Verstappen won his first World Championship (and the first for a Dutch driver), driving for Red Bull Racing-Honda.
Lewis Hamilton, the defending champion, finished runner-up, driving for Mercedes.
Hamilton's teammate Valtteri Bottas was third, driving for Mercedes.
Mercedes won their eighth consecutive Constructors' Championship.
At season's end in Abu Dhabi, Max Verstappen of Red Bull Racing-Honda won the Drivers' Championship for the first time in his career. Verstappen became the first ever driver from the Netherlands, the first Honda-powered driver since Ayrton Senna in 1991, the first Red Bull driver since Sebastian Vettel in 2013 and the first non-Mercedes driver in the turbo-hybrid era to win the World Championship.
Honda became the second engine supplier in the turbo-hybrid era to power a championship winning car, after Mercedes. Four-time defending and seven-time champion Lewis Hamilton of Mercedes finished runner up. Mercedes retained the Constructors' Championship for the eighth consecutive season.
The season ended with a controversial finish, with the two title rivals for the drivers' crown entering the last race of the season with equal points. Verstappen sealed the title after winning the season-ending Abu Dhabi Grand Prix after a last-lap restart pass on Hamilton following a contentious conclusion of a safety car period. Mercedes initially protested the results, and later decided not to appeal after their protest was denied. The incident led to key structural changes to race control, including the removal of Michael Masi from his role as race director and the implementation of a virtual race control room, who assist the race director. Unlapping procedures behind the safety car were to be reassessed and presented by the F1 Sporting Advisory Committee prior to the start of the 2022 World Championship season. On 10 March 2022 the FIA World Motor Sport Council report on the events of the final race of the season was announced, and that the "Race Director called the safety car back into the pit lane without it having completed an additional lap as required by the Formula 1 Sporting Regulations", however also noted that the "results of the 2021 Abu Dhabi Grand Prix and the FIA Formula One World Championship are valid, final and cannot now be changed".
This was the first season since 2008 where the champion driver was not from the team that took the constructors' title.
"""
print(original_text)
As we can see, this is a very long article, and summarizing it will make it significantly easier for us to be able to distinguish the truly important moments of the season from the small unimportant details.
Now, we summarize the article.
summarization = pipeline("summarization")
summary_text = summarization(original_text)[0]['summary_text']
And finally, we print the summarized article.
print("Summary:", summary_text)
This particular segment of code produces the following output, which is a summarized version of the original article:
"Summary: The 2021 Formula One World Championship was the 72nd running of the Fédération Internationale de l'Automobile (FIA), the governing body of international motorsport. The championship was contested over twenty-two Grands Prix, and held around the world. Drivers and teams competed for the titles of World Drivers' Champion and World Constructors' Champion. Max Verstappen of Red Bull Racing-Honda won the Drivers' Championship for the first time in his career. Lewis Hamilton of Mercedes finished runner-up, driving for Mercedes. Mercedes retained their eighth consecutive constructors' Championship."
As we can see, this summary only tells us about the most important events that took place over the course of the season. It tells us what the article is about (that is, the 2021 Formula One World Championship), how many races were held in total, it mentions which team and driver won their respective championships, and gives us an insight into how the season affected all of the parties involved. This shortened version of the article is concise, easy to read, and grammatically sound. It conveys the highlights of the article and leaves out anything that might not be significant to the reader.
Conclusion
In this article at OpenGenus, we learned about the fundamentals of Text Summarization, the different methods that we use to summarize text, namely: Extractive Text Summarization and Abstractive Text Summarization, Transformers, the BART model, and we also worked with a practical model (in Python) in order to summarize a block of text.
Thanks for reading!