
In BERT, GELU is used as the activation function instead of ReLU and ELU. In this article, we have explained (both based on experiments and theoretically) why GELU is used in BERT model.
After reading this article at OpenGenus you will be able to address:
Why GELU activation function is used for BERT?
Table of contents:
- Experiments
- Theoretical reason
- Conclusion
Pre-requisites:
Experiments
Based on experiments:
- GELU gives better accuracy in BERT model compared to ReLU and ELU.
- On using approximation for GELU, model performance is comparable to ReLU and ELU.
- When trained with Adam optimizer, GELU gives the least error rate on median (NOT on average).
- The exact accuracy comparison depends on the Model we are dealing with.
Theoretical reason
Theoretical reason why GELU is used in BERT:
- GELU and ReLU are very similar yet GELU relies on the value and ReLU relies on the sign of the value.
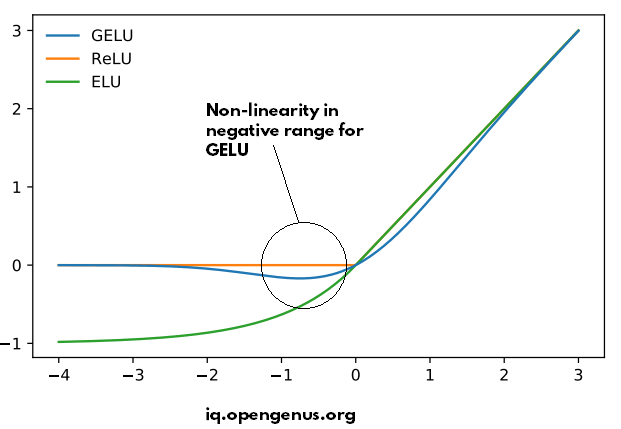
- ReLU becomes 0 in the negative rage suddenly. On contrast, GELU maintains a small non-linearity in the negative range (for a small range) before becoming zero. Hence, GELU is much smoother than ReLU in this respect.
- This is a benefit in BERT.
- As a small non-linearity is the negative range helps maintain the long relation tracking as in BERT. Note that is the negative range is increased, the benefit is nullified as in ELU.
- This fixes the "Dying RELU" problem in case of ReLU.
- Intuitively, the features capturing the relationship between two states in BERT has small values (close to 0 and even, becomes negative). This is because this acts a weak linking. GELU helps these linking propagate across the network.
Following image demonstrates the non-linearity in the negative range of GELU:
-
GELU can be approximated more accurately compared to other activation functions. This has performance implications.
-
GELU performs well (in terms of accuracy) when attention layer is involved.
-
ReLU is still used in popular models like ResNet50 where GELU fails to bring in consistent accuracy improvement.
Conclusion
Today, the understanding of parts of Neural Network is not complete and hence, it is difficult to accurately predict which activation function will perform best for a given Deep Learning model.
The current strategy is to select specific activation function intuitively based on the few properties we have identified and then, select one based on experiments.
With this article at OpenGenus, you must have a better idea of why GELU is used in BERT. This is an open-research problem.