
ALBERT stands for A Lite BERT and is a modified version of BERT NLP model. It builds on three key points such as Parameter Sharing, Embedding Factorization and Sentence Order Prediction (SOP).
Introduction
With the development of transformer architecture and BERT had led to the development of very powerful language models which had reached state-of-the-art results in various NLP tasks such as machine translation and question answering. These models are pre-trained and then tailored for particular downstream tasks using specific dataset which is way smaller than dataset needed for pre-trained model.
How it started?
Bidirectional Encoder Representations from Transformers (BERT) is a Transformer-based language model which utilizes pre-training methods for natural language understanding. It works by utilizing Masked LM and Next sentence prediction. To know more about BERT, click here.
To achieve high accuracy and have state-of-the-art results, these models have to be way larger than usual. They have millions or sometimes billions of parameters to achieve high accuracy. Now, if someone wants to scale such large models, they are limited by memory size and computational power. Due to these limitations researchers at Google looked into parameter reduction without affecting the performance.
ALBERT
Let us now look what ALBERT did different than BERT to improve upon it.
How ALBERT improved upon BERT?
- Parameter Sharing:
Most language model like BERT have different parameters for different encoder layers. For example, BERT have 12 layer of encoders and each layer have different parameters. But ALBERT have same weights across different layers. So, we can say that ALBERT have one encoder layer with different weight and apply that layer 12 times on the input. As a result, the large ALBERT model has about 18x fewer parameters compared to BERT-large. This concept reduces the size of BERT to huge extent.
- Embedding Factorization:
In BERT, all the output of intermediate layers are same and the vocabulary size. But this was isolated in ALBERT. Rather than having embeddings size same as vector size that are passed between these encoder layers, they reduced the size of embeddings. This is done by using a matrix which multiplies with embeddings and blows up the size equals to hidden layer vector. This saves a lot of total number of parameters in the model. The image below shows the difference in the total number of parameters between BERT and ALEBRT.

- Sentence Order Prediction (SOP):
BERT used NSP loss which means whether two sentences appear consecutively or not. It was used as NSP technique would improve upon the performance of the model in downstream tasks such as NLI, but subsequent studies found this to be unreliable and hence, it was removed from ALBERT. Rather it used a complex loss called SOP loss. This loss is based on coherence of sentences rather than just predicting the topics.
The Dataset
For pre-training task of ALBERT baseline model, researchers at Google used the BOOKCORPUS and English Wikipedia dataset, which together contain data size of around 16GB of text.
Results
Test results show that the ALBERT language model significantly outperformed the BERT language model on the standard language benchmark tests such as SQuAD1.1, SQuAD2.0, MNLI SST-2, and RACE.

Both ALBERT single-model and it's ensemble model improved on previous state-of-the-art results on these three benchmarks. It produced a GLUE score of 89.4, RACE test accuracy of 89.4 and a SQuAD 2.0 test F1 score of 92.2.
The image below shows the results for GLUE benchmarks and further below shows results on e SQuAD and RACE benchmarks.
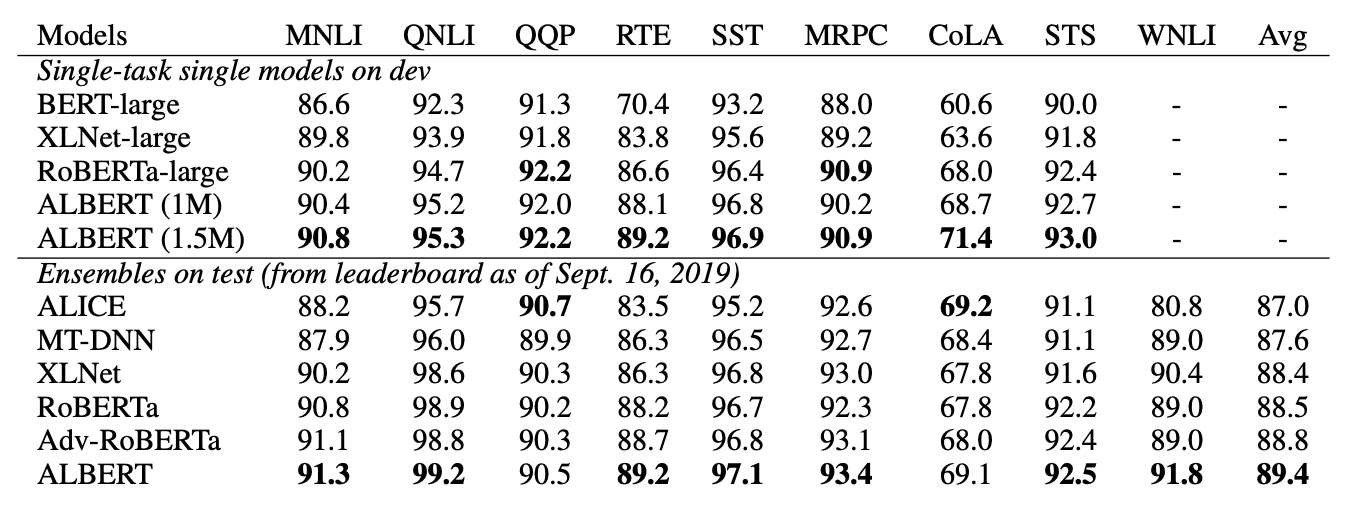
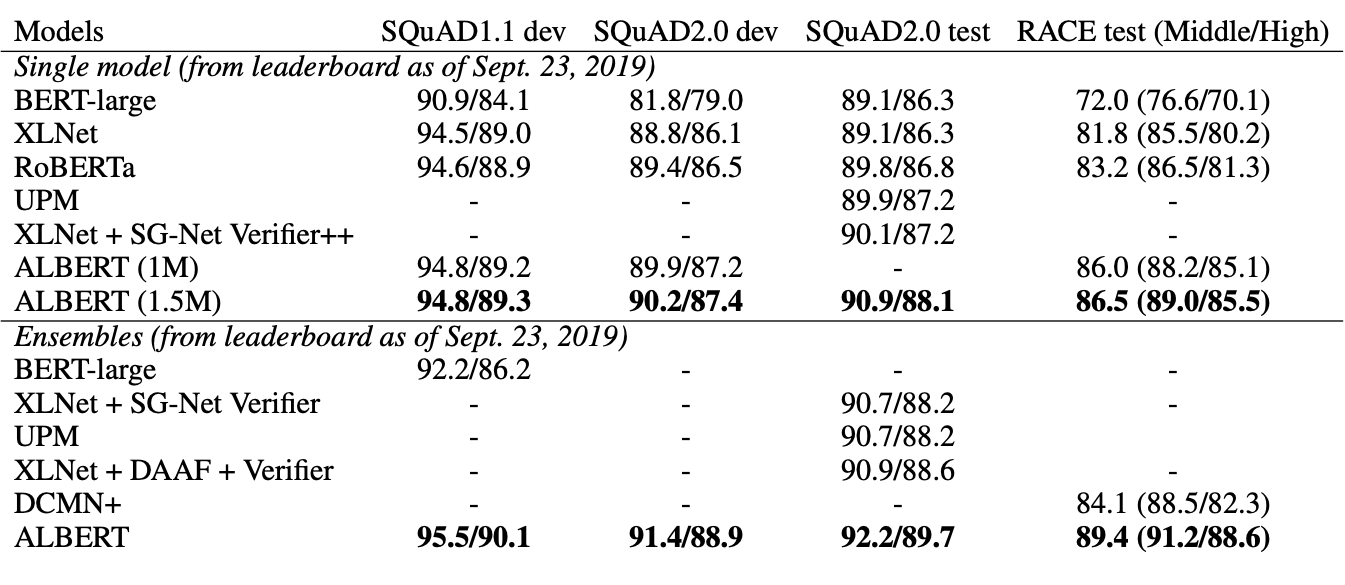
To know more about ALBERT, do check out the research paper.