
Get this book -> Problems on Array: For Interviews and Competitive Programming
Reading time: 40 minutes | Coding time: 15 minutes
We will walk through the basic ideas of Least Recently Used (LRU) cache and used 2 data structures namely Doubly Linked List and Hash Map to implement it from scratch and compared the performance of LRU with FIFO cache.
Cache is a small amount of very fast and expensive memory which we get in our processors and RAMs. Since its expensive, its usage has to be highly optimized! One such way is to use the Least Recently Used (LRU) Cache Algorithm also known as one of the Page Replacement Algorithms. It maintains the things that need to be stored in cache and which are to be thrown out.
Overview
I will explain this with an example:
When you are working on a part of a coding project, you would be opening some specific files, say like project.cpp, project1.cpp, again and again. This means if you were earlier playing some game, the files of that game are no longer used frequently.
Now, you opened a text file and closed it and you have no plan on opening it again in sometime. Your concious should say that it should be removed from the cache. LRU Cache exactly does that for you.
LRU Cache gives priority to those files which are used more frequently. The files that are used rarely are removed and those which are used frequently are stored. The least recently used file is removed when any new file is used. To get more insight on how it works, see our implementation (part of OpenGenus) of it.
Logic and Implementation
There are many ways to implement the algorithm. I have used:
- a Doubly Linked List for Cache
- a Hash Map for storing key and corresponding nodes
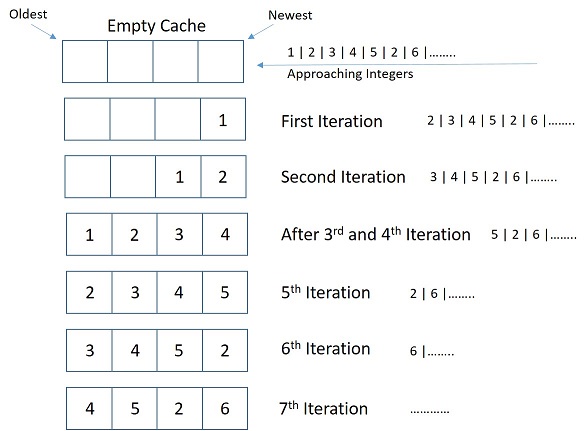
Consider a stream of integers approaching the cache memory. Let size of cache be 4, i.e, it can hold 4 integers.
When the cache is empty, it stores the first integer, say 1, also this is a Cache Miss or "Fault". The next integer is 2. Since it is not in cache it gets stored too. Next come 3 & 4 and those also get stored. Now the next integer coming is 5.
We have already filled up our cache, so we need to remove something. Now, since 1 was added earliest and is not used again, it gets removed and 5 gets stored in the "head" of the doubly linked list, i.e, on first position.
Now the new integer coming is 2. Now, we already have 2 in our Cache (A Cache Hit!). This is the point where LRU cache has its core. We update the position of 2 to be the newest.
Now, if an integer 6 comes up, we would not delete 2, instead 3 gets removed since it was used the earliest. The pictorial representation would clear your doubts, if any.
The hash map stores the key and the corresponding node at which that key is present. The node or "dll" (see code) has a 3 data points:
-
first is an integer "value" which stores the generated random number
-
two pointers to "dll" to store the address of left and right or previous and next node of the doubly linked list or say "cache".
-
The function "make_hash" recieves the map to which the key:address pair is to stored, the key and the address itself. This function adds the key address pair to the corresponding hashmap.
-
"add_to_cache" function recieves the hashmap, pointer to the pointer of head and end of the doubly linked list or cache, the key and the amount of cache size used. It makes a new node and adds to the fron of the cache. Note that it is only called when the cache size is not fully used.
-
The function "LRUCache" is the implementation or meat of our algorithm. it recieves the haspmap, key, pointer to pointer of head and end, and the size of cache. Firstly it checks whether we already have the key present, for this, it sees the hashmap. If the key is not present, it then checks if the cache has free space or full. If there is free space, it calls the "add_to_cache", else, it modifies the
cache by adding the a new "dll" to the "head" of the cache and removes the last element of the cache. The new "end" is the last second element of the previous cache. Now, if the key is present, we modify the cache. The node that has this key is made the head and the adjacent two nodes are connected to each other. This way, the recently used key is updated so that, it doesn't get removed over a key which is less used. Note that we only remove nodes from the end of the cache as that is the least recently used node.
C++ Code
I have added implementation for First In First Out (FIFO) Cache also, so that you can understand the difference between the two algorithms. You can comment out that. I advise you to try play with the cache size and number of integers in the stream.
#include <iostream>
#include <map>
using namespace std;
int LRUcachehits=0;
int LRUcachemiss=0;
int LRUcacheused=0;
bool LRUcachefull=false;
int FIFOcacheused=0;
int FIFOcachehits=0;
int FIFOcachemiss=0;
bool FIFOcachefull=false;
struct dll{
int value;
struct dll* left;
struct dll* right;
};
map<int,dll*> mymapLRU;
map<int,dll*> mymapFIFO;
void make_hash(map<int,dll*> &mymap,int key,dll* address){
mymap[key]=address;
}
void add_to_cache(int key,map<int,dll*> &mymap,dll** head,dll** end,int* cused){
//This function adds nodes to the duoubly linked list
dll* temp=*head;
if((*cused)==0)
{
(*head)->value=key;
(*head)->left=NULL;
(*head)->right=NULL;
*end=*head;
make_hash(mymap,key,*head);
}
else
{
dll* temp2=new(dll);
temp->left=temp2;
temp2->right=temp;
temp2->left=NULL;
temp2->value=key;
*head=temp2;
make_hash(mymap,key,*head);
}
}
void LRUCache(int x,map<int,dll*> &mymapLRU,dll** head,dll** end,int csize){
if(mymapLRU.find(x)==mymapLRU.end())
{
//current key or random number is not available in the current hash map
FILE *pfile;
pfile=fopen("log_LRUCache.txt","a");
fprintf(pfile,"Cache Miss for key = %d\n",x);
LRUcachemiss++;
fclose(pfile);
if(!LRUcachefull)
{
//If the cache capacity is not fully utilized, more nodes are added
add_to_cache(x,mymapLRU,head,end,&LRUcacheused);
FILE *pfile;
pfile=fopen("log_LRUCache.txt","a");
fprintf(pfile,"Key Added to cache !\n");
fclose(pfile);
LRUcacheused++;
if(LRUcacheused==csize)
LRUcachefull=true;
}
else
{
//If the cache is fully utilized, the least used element or element at last is removed
mymapLRU.erase(mymapLRU.find((*end)->value));
dll* temp=(*end)->left;
temp->right=NULL;
delete *end;
*end=temp;
dll* temp2=new(dll);
temp2->value=x;
temp2->right=*head;
temp2->left=NULL;
(*head)->left=temp2;
*head=temp2;
make_hash(mymapLRU,x,*head);
}
}
else
{
//Its a Cache Hit! Below code updates the position of the current key to be the head
FILE *pfile;
pfile=fopen("log_LRUCache.txt","a");
fprintf(pfile,"Cache Hit for key = %d!\n",x);
LRUcachehits++;
fprintf(pfile,"Total Cache Hits = %d\n",LRUcachehits);
fclose(pfile);
dll* temp;
temp=mymapLRU.find(x)->second;
if(temp!=*head)
{
dll* left=temp->left;
dll* right=temp->right;
temp->right=*head;
temp->left=NULL;
(*head)->left=temp;
*head=temp;
left->right=right;
if(right!=NULL)
right->left=left;
else
*end=left;
}
}
}
void FIFOCache(int x,map<int,dll*> &mymapFIFO,dll** head,dll** end,int csize){
if(mymapFIFO.find(x)==mymapFIFO.end())
{
FILE *pfile;
pfile=fopen("log_FIFOCache.txt","a");
fprintf(pfile,"Cache Miss for key = %d\n",x);
FIFOcachemiss++;
fclose(pfile);
if(!FIFOcachefull)
{
add_to_cache(x,mymapFIFO,head,end,&FIFOcacheused);
FILE *pfile;
pfile=fopen("log_FIFOCache.txt","a");
fprintf(pfile,"Key Added to cache !\n");
fclose(pfile);
FIFOcacheused++;
if(FIFOcacheused==csize)
FIFOcachefull=true;
}
else
{
mymapFIFO.erase(mymapFIFO.find((*end)->value));
dll* temp=(*end)->left;
temp->right=NULL;
delete *end;
*end=temp;
dll* temp2=new(dll);
temp2->value=x;
temp2->right=*head;
temp2->left=NULL;
(*head)->left=temp2;
*head=temp2;
make_hash(mymapFIFO,x,*head);
}
}
else
{
FILE *pfile;
pfile=fopen("log_FIFOCache.txt","a");
fprintf(pfile,"Cache Hit for key = %d!\n",x);
FIFOcachehits++;
fprintf(pfile,"Total Cache Hits = %d\n",FIFOcachehits);
fclose(pfile);
}
}
void printdll(dll* head){
dll* temp=head;
while(temp!=NULL)
{
cout<<temp->value<<" ";
temp=temp->right;
}
cout<<endl;
}
void testcache(int csize,int totrand){
//srand ( time(NULL) );
dll* headLRU=new(dll);
dll* endLRU;
dll* headFIFO=new(dll);
dll* endFIFO;
cout<<" # Testing for Cache Size " <<csize<< " and Random Data of "<<totrand<<" integers!"<<endl;
FILE *pfile;
pfile=fopen("log_LRUCache.txt","a");
fprintf(pfile,"____Cache Size %d | Random Data %d integers____\n",csize,totrand);
fclose(pfile);
pfile=fopen("log_FIFOCache.txt","a");
fprintf(pfile,"____Cache Size %d | Random Data %d integers____\n",csize,totrand);
fclose(pfile);
for(int i=0;i<totrand;i++)
{
int a=rand()%100+1;
LRUCache(a,mymapLRU,&headLRU,&endLRU,csize);
FIFOCache(a,mymapFIFO,&headFIFO,&endFIFO,csize);
}
cout<<" Total LRUCache Hits : "<<LRUcachehits<<endl;
cout<<" Total LRUCache Miss : "<<LRUcachemiss<<endl;
cout<<" Total FIFOCache Hits : "<<FIFOcachehits<<endl;
cout<<" Total FIFOCache Miss : "<<FIFOcachemiss<<endl;
cout<<endl;
}
void autotest(int csize,int totrand){
LRUcachehits=0;
LRUcachemiss=0;
LRUcacheused=0;
LRUcachefull=false;
FIFOcacheused=0;
FIFOcachehits=0;
FIFOcachemiss=0;
FIFOcachefull=false;
mymapLRU.clear();
mymapFIFO.clear();
testcache(csize,totrand);
}
int main()
{
cout<<"Enter number of tests you want to perform : ";
int t=0;
cin>>t;
int totrandarray[]={100,250,500,1000,5000,10000,15000};
int csizearray[]={4,8,16,32,64};
for(int j=0;j<t;j++)
{
cout<<"Test : #"<<j+1<<" : "<<endl;
for (int k=0;k<5;k++)
{
for(int n=0;n<7;n++)
{
autotest(csizearray[k],totrandarray[n]);
}
}
}
return 0;
}
If you have played with the code a bit, you might be wondering, "well this has no advantage over FIFO Cache as the cache hits are more in any of the algorithms". Yes, you are right! This kind of unbiased data does not show the power of LRUCache. Try making the generated random numbers to be a bit biased and feel the difference!
Add the following code in place of :
int a = rand() % 100 + 1;
with
int b = rand() % 3 + 1;
int a = 0;
if(b == 1)
a = rand() % 50 + 1;
else
a = rand() % 50 + 51;
I have added a bar graph that shows the difference in the two algorithms when we increase the input data. The data is for 64 units size of cache and is average of 5 tests. The data was biased and made by the above code.
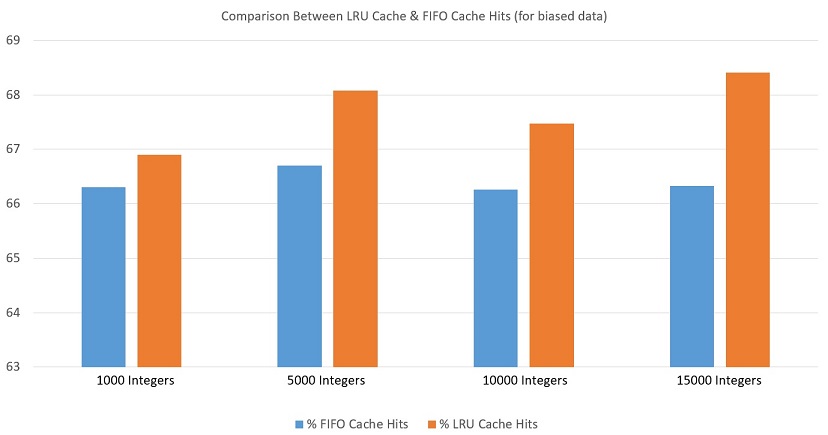
Note : The time complexity for both the algorithms is same as the additional methods (modifying cache) in LRU Cache take O(1) time.
Both algorithms work on log(n) as the find() method of map take log(n) time.
Applications
Following are the applications of Least Recently Used cache:
- Applications in your Phone's Home Screen
The idea is to keep applications which will be used frequently on the home screen and LRU cache works on the same principles. Hence, your Phone's Operating System uses LRU cache ideas to implement this.
- Caching Bitmap with LRU cache
The idea of caching bitmaps is to cache data that is used frequently. Such data includes images and more. This is replicated using LRU cache ideas.
Read details on Android Developer Documentations