
Reading time: 30 minutes | Coding time: 10 minutes
In this article we will work on Luhns Heuristic Method for text summarization. This is one of the earliest approaches of text summarization. Luhn proposed that the significance of each word in a document signifies how important it is. The idea is that any sentence with maximum occurances of the highest frequency words(Stopwords) and least occurances are not important to the meaning of document than others. Although it is not considered very accurate approach.
Introduction
Luhn’s algorithm is an approach based on TF-IDF. It selects only the words of higher importance as per their frequency. Higher weights are assigned to the words present at the begining of the document. It considers the words lying in the shaded region in this graph:
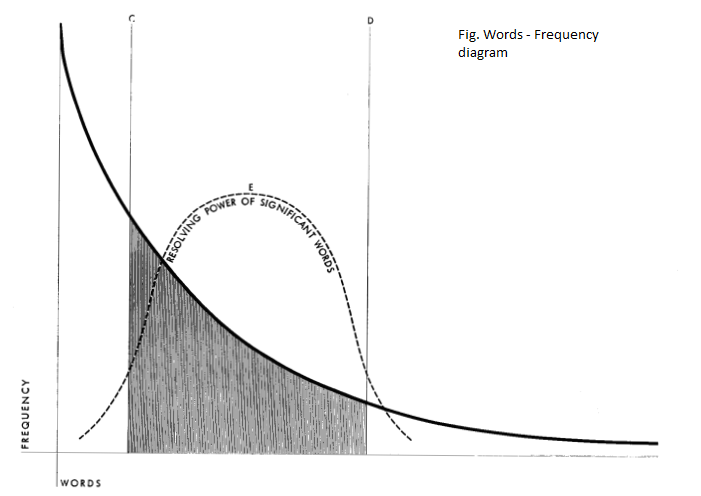
The region on the right signifies highest occuring elements while words on the left signifies least occuring elements. Luhn introduced the following criteria during text preprocesing:
- Removing stopwords
- Stemming (Likes->Like)
In this method we select sentences with highest concentration of salient content terms. For example , if we have 10 words in a sentence and 4 of the words are significant.
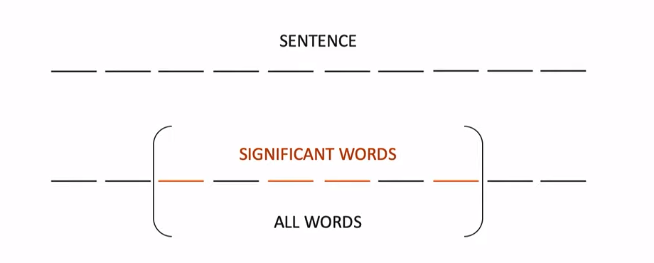
For calculating the significance instead of number of significant words by all words
here we divide them by the span that consist of these words. Thus the Score obtained from our example would be
Application
The Luhns method is most significant when:
- Too low frequent words are not significant
- Too high frequent words are also not significant (e.g. “is”, “and”)
- Removing low frequent words is easy
- set a minimum frequency-threshold
- Removing common (high frequent) words:
- Setting a maximum frequency threshold (statistically obtained)
- Comparing to a common-word list
- Used for summarizing technical documents.
Algorithm
Luhns method is a simple technique in order to generate a summary from given words. The algorithm can be implemented in two stages.
In the first stage, we try to determine which words are more significant towards the meaning of document. Luhn states that this is first done by doing a frequency analysis, then finding words which are significant, but not unimportant English words.
In the second phase, we find out the most common words in the document, and then take a subset of those that are not these most common english words, but are still important. It usually consists of following three steps:
- It begins with transforming the content of sentences into a mathematical expression, or vector(represented below through binary representation). Here we use a bag of words , which ignores all the filler words. Filler words are usually the supporting words that do not have any impact on our document meaning. Then we count all the valuable words left to us. For example,
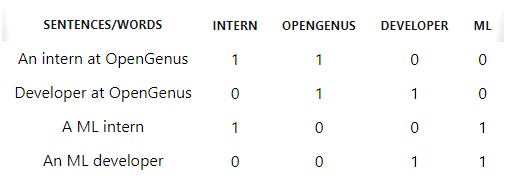
In the above table we can clearly see that the words like an and a that are the stopwords are not considered while evaluation.
- In this step we use evaluate sentences using sentence scoring technique. We can use the scoring method as illustrated below.
A span here refers to the part of sentence(in our case)/document consisting all the meaningful words.
Tf-idf can also be used in order to prioritize the words in a sentence.
- Once the sentence scoring is complete, the last step is simply to select those sentences with the highest overall rankings.
Working
First step is to load the file or document for summarization. Let us assume we have any file words.txt
'''In this function we load our file and thus take each sentence indivisually in lowercase.'''
def load_common_words():
f = open("words.txt", "r")
common_words = set()
for word in f:
common_words.add(word.strip('\n').lower())
f.close()
return common_words
In the next step we try to find the most common words to our document base don their frequency. We also try to remove the unwanted stopwords.
def top_words(file_name):
f = open(file_name, "r")
record = {}
common_words = load_common_words()
for line in f:
words = line.split()
for word in words:
w = word.strip('.!?,()\n').lower()
if record.has_key(w):
record[w] += 1
else:
record[w] = 1
for word in record.keys():
if word in common_words:
record[word] = -1
f.close()
occur = [key for key in record.keys()]
occur.sort(reverse=True, key=lambda x: record[x])
return set(occur[: len(occur) / 10 ])
The code below is used to calculate the score of sentences
def calculate_score(sentence, metric):
words = sentence.split()
imp_words, total_words, begin_unimp, end, begin = [0]*5
for word in words:
w = word.strip('.!?,();').lower()
end += 1
if w in metric:
imp_words += 1
begin = total_words
end = 0
total_words += 1
unimportant = total_words - begin - end
if(unimportant != 0):
return float(imp_words**2) / float(unimportant)
return 0.0
In the final step we generate our summary
def summarize(file_name):
f = open(file_name, "r")
text = ""
for line in f:
text += line.replace('!','.').replace('?','.').replace('\n',' ')
f.close()
sentences = text.split(".")
metric = top_words(file_name)
scores = {}
for sentence in sentences:
scores[sentence] = calculate_score(sentence, metric)
top_sentences = list(sentences) # make a copy
top_sentences.sort(key=lambda x: scores[x], reverse=True) # sort by score
top_sentences = top_sentences[:int(len(scores)*ABSTRACT_SIZE)] # get top 5%
top_sentences.sort(key=lambda x: sentences.index(x)) # sort by occurrence
return '. '.join(top_sentences)
Quick Implementation
We can implement Luhns Heuristic methon quickly by using sumy in python.
from sumy.parsers.plaintext import PlaintextParser
from sumy.nlp.tokenizers import Tokenizer
from sumy.summarizers.luhn import LuhnSummarizer
It will import all the packages needed for performing summarization.
#Taking a document to be summarized
doc="""OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life. """
print(doc)
Output
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
OpenGenus is all about positivity and innovation.
Over 1000 people have contributed to our missions and joined our family. We have been sponsored by three great companies namely Discourse, GitHub and DigitalOcean. We run one of the most popular Internship program and open-source projects and have made a positive impact over people's life.
In the next step, we will summarize our document using Luhns method.
# For Strings
parser=PlaintextParser.from_string(doc,Tokenizer("english"))
# Using KL
summarizer = LuhnSummarizer()
#Summarize the document with 4 sentences
summary = summarizer(parser.document,2)
Finally, we have out summary
for sentence in summary:
print(sentence)
Output
OpenGenus Foundation is an open-source non-profit organization with the aim to enable people to work offline for a longer stretch, reduce the time spent on searching by exploiting the fact that almost 90% of the searches are same for every generation and to make programming more accessible.
Over 1000 people have contributed to our missions and joined our family.
Conclusion
From the above article we learned about the Luhns Heuristic method for text summarization. In the end , following conclusions can be drawn :
- Criteria for sentence selection:
- Word frequency
- Phrase frequency
- Type of document: single
- Corpus suited: Technical articles (like OpenGenus IQ articles) and documents
- Advantages: Frequent words are present in summary
- Disadvantages: Redundancy and Low accuracy
Further Reading
- Introduction to Luhn's Algorithm (PDF) by UC Berkeley
- Summarization techniques (PDF) by CMU