
In this article, we will go over 70 questions that cover everything from the very basics of Text Summarization to the evaluation of summarized pieces of text using various metrics.
1. What is Text Summarization?
Answer: Text Summarization is the process of shortening a long piece of text, such as an article or an essay, into a summary that conveys the overarching meaning of the text by retaining key information and leaving out the bits that are not important.
2. What are the two broad categories of Text Summarization?
Answer: The two broad categories of Text Summarization are- Extractive Summarization and Abstractive Summarization.
3. Explain what Extractive Summarization models do.
Answer: Extractive Summarization models concatenate several relevant, information-containing sentences exactly as they are in the source material in order to create short summaries. Every sentence in the summary exists in the original piece of text.
4. Explain what Abstractive Summarization models do.
Answer: Abstractive Summarization models create summaries that convey the main information in the source material and might reuse certain phrases and clauses from it, but the overall summary is generally rephrased and written in different words. Sentences in the summary may not necessarily be present in the original piece of text.
5. Which of the two are generally more computationally expensive: Extractive Summarization models or Abstractive Summarization models? Why?
Answer: Abstractive Summarization models generally require more computational power. This is because they need to generate grammatically and contextually intact sentences that are relevant to the domain that is being referred to. The model has to first thoroughly understand the source material in order for it to be able to summarize it effectively and meaningfully.
6. Which of the two are more widely used to summarize text: Extractive Summarization models or Abstractive Summarization models? Why?
Answer: Extractive Summarization models are more widely used. This is because they are simpler than Abstractive Summarization models, as their sole responsibility is to identify the important sentences that should be a part of the summary. Abstractive Summarization models have to take many more details into account before being able to generate a summary.
7. What is the difference between indicative and informative summaries?
Answer: A summary that enables the reader to determine the about-ness of the source material, such as the length and the writing style, is called an indicative summary, whereas a summary that can be read in place of the source material is called an informative summary. Informative summaries include facts that are present in the source material.
8. What are keyword and headline summaries?
Answer: Keyword summaries consist of a set of indicative words or phrases mentioned in the source material, whereas headline summarization deals with summarizing the entire source material in just a single sentence, or a 'headline'.
9. What is Generic Summarization?
Answer: Generic Summarization aims at summarizing text while making very few assumptions about the domain of the source material, the target audience, as well as the goal of producing the summary. The importance of information is determined with respect to the content of the input alone. It is further assumed that the summary will help the reader quickly determine what the document is about, thus perhaps negating the need for them to read the document itself.
10. What is Query Focused Summarization?
Answer: In query focused summarization, the goal is to summarize only the information in the input document(s) that is relevant to a specific user query. For example, if a user generates a query and a set of relevant documents are retrieved by the search engine, a summary of each document could make it easier for the user to determine which document is relevant. To generate a useful summary in this context, an automatic summarizer needs to take the query into account as well as the document. The summarizer tries to find information within the document that is relevant to the query or in some cases, may indicate how much information in the document relates to the query. This is commonly seen in search engines today.
11. What is Update Summarization?
Answer: Update Summarization is a form of summarization that is sensitive to time, wherein a summary of a dataset is generated based on the assumption that the user has already read a given set of documents. In other words, the summary must convey the important development of an event beyond what the user has already seen.
12. What does 'sentence extraction' refer to in the context of Text Summarization?
Answer: Sentence extraction is one of the primary focuses of most Text Summarization systems today. These systems have to essentially find out which sentences in a given piece of text are important so that they can be 'extracted', and considered a part of the summary. These sentences are deemed 'important' on the basis of many different parameters, such as the presence of multiple descriptive words close to each other in a single sentence, which can indicate that the sentence conveys important information, or the repeated use of a particular word, which can indicate the main topic of the document, and so on.
13. Since the repeated use of a particular word in a piece of text could point to the main topic of a document, what can be done to deal with common words that are in no way descriptive of the document's content, such as 'and', 'or', 'the', etc.?
Answer: Since function words such as determiners, prepositions and pronouns do not have much value in telling us what the document is about, we can use a predefined list, commonly called a stop word list, consisting of such words to remove them from consideration.
14. Elaborate on a drawback of Extractive Summarization models.
Answer: Since Extractive Summarization models' sole emphasis is on identifying the important sentences that should appear in the summary, and since they can't thoroughly learn about the source material the way Abstractive Summarization models can, they do not always present the summarized sentences in the most meaningful order. This is something that newer non-extractive models fix via 'sentence ordering'.
15. What is BLEU?
Answer: BiLingual Evaluation Understudy, or BLEU, is an evaluation metric that is widely used for machine translation, text generation, and for models having a sequence of words as their output. BLEU scores range from 0 to 1, where a score of 0 signifies no match between the predicted output and the expected output, and a score of 1 signifies a perfect match between the predicted output and the expected output.
16. What is 'sentence revision' in the context of Text Summarization?
Answer: Sentence revision involves re-using text collected from the input to the summarizer, but parts of the final summary are automatically modified by substituting some expressions with other more appropriate expressions, given the context of the new summary. Types of revisions proposed by early researchers include the elimination of unnecessary parts of the sentences, the combination of information originally expressed in different sentences and the substitution of a pronoun with a more descriptive noun phrase where the context of the summary requires this.
17. What is 'sentence fusion' in the context of Text Summarization?
Answer: Sentence fusion is the process of taking two sentences that have overlapping information and also fragments that are different, and producing a new sentence that conveys the information in both sentences without any redundancy.
18. What is 'sentence compression' in the context of Text Summarization?
Answer: Sentence compression refers to the process of removing unimportant or inconsequential parts of a sentence in order to make it more concise and easier to read.
19. What is 'maximal marginal relevance' in the context of Text Summarization?
Answer: Maximal marginal relevance, or MMR, was an early summarization approach for both generic as well as query focused summarization, in which summaries are created using greedy, sentence-by-sentence selection. At each selection step, the greedy algorithm selects the sentence that is most relevant to the user query and least relevant to the sentences that are already a part of the summary.
20. What method of Text Summarization can be applied on a piece of text that contains unclear phrases and sub-par linguistic quality?
Answer: If we want to produce a summary of a piece of text that hasn't been written very concisely, it's best if we use Abstractive Summarization. This is because an abstractive model will allow us to rewrite unclear phrases, cut and paste bits from different sentences, and paraphrase, in order to produce a much more readable summary. If we use Extractive Summarization, the summary will contain the same unclear phrases as the source material, thus making it more difficult to read.
21. What is TF-IDF?
Answer: Term Frequency-Inverse Document Frequency, or TF-IDF, is a numerical statistic that is used to determine how important a word is to a document in a collection of written texts. It is often used as a weighting factor in searches of information retrieval, text mining, and user modeling.
The TF-IDF value increases proportionally to the number of times a word appears in the document and is compensated for by the number of documents in the collection that contain the word, which helps to adjust for the fact that some words appear more frequently than others in general.
22. What are Transformers?
Answer: Transformers are a type of neural network architecture. They avoid using the principle of recurrence, and work entirely on an attention mechanism to draw global dependencies between the input and the output. Transformers allow for much more parallelization than sequential models, and can achieve very high translation quality even after being trained only for short periods of time. They can also be trained on very large amounts of data without as much difficulty. Transformer models such as the BART model are used for various Natural Language Processing (NLP) tasks, such as paraphrasing, summarization, and abstractive question answering.
23. What is Single Document Summarization?
Answer: 'Single document' Summarization is the process of generating a representative summary of a single input document.
24. What is Multi-Document Summarization?
Answer: 'Multi-document' Summarization is a process that aims at extracting information from multiple texts written about the same topic. The resulting summary report allows users to quickly familiarize themselves with information contained in a large cluster of documents at once.
25. What is Aided Summarization?
Answer: When we require a very high degree of summarization quality, we need to combine the efforts of both humans as well as software. In Aided Summarization, a human post-processes the software output, in the same way that one edits the output of an automatic translation by Google Translate.
26. Name a few techniques used to evaluate the informativeness of software-generated summaries.
Answer: The most common method of evaluating software-generated summaries is to compare them with human-made summaries.
Some techniques of evaluation are as follows-
- Intrinsic Evaluation
- Extrinsic Evaluation
- Inter-textual Evaluation
- Intra-textual Evaluation
27. What is the main difference between Intrinsic Evaluation and Extrinsic Evaluation?
Answer: Intrinsic Evaluations test summarization systems in a vacuum, that is, without any concern for other tasks. They mainly assess the coherence and the informativeness of summaries. Extrinsic Evaluations, on the other hand, test summarizations based on how they affect some other task, such as reading comprehension and relevance assessment.
28. What is the main difference between Inter-textual Evaluation and Intra-textual Evaluation?
Answer: Intra-textual Evaluation methods asses the output of a specific summarization system, whereas Inter-textual Evaluation methods focus on contrastive analysis of the output produced by several summarization systems.
29. What are Sequence-To-Sequence (seq2seq) models?
Answer: Typically, RNNs have fixed-size input and output vectors. This isn't desirable in use cases such as speech recognition and machine translation, where the input and output sequences do not need to be fixed and of the same length. For example, if we have to translate a sentence from one language to another, the original sentence and the translated sentence will likely have different sequence lengths, and neither of these sequence lengths are predefined to begin with. Thus, if we wish to employ an RNN for this task, we will have to do so without defining the sequence lengths beforehand. This is where Sequence-To-Sequence models make things easier.
Sequence-To-Sequence models consist of an encoder as well as a decoder network, and when given an input, the encoder turns each item into a corresponding hidden vector containing the item and its context. The decoder reverses the process, turning the vector into an output item, using the previous output as the input context.
Sequence-To-Sequence models can be implemented for Text Summarization as well, since Text Summarization involves working with sequential information.
30. What can be considered a drawback of the evaluation techniques that are used to test automatic summaries today?
Answer: One of the main drawbacks of the evaluation techniques used today is the fact that we need at least one reference summary, and in some cases, multiple reference summaries, in order for us to be able to compare automatic summaries with their corresponding models. This can be time consuming and expensive.
31. What is 'tokenization'?
Answer: Tokenization is the process of splitting a text object into smaller units, which are known as tokens. A very commonly used tokenization method is whitespace tokenization.
For example, if we have the sentence:
"George ate an apple this morning."
Then, after the tokenization process, we will be left with the following tokens:
"George", "ate", "an", "apple", "this", "morning."
32. What is 'stemming'?
Answer: Stemming is the process of removing inflationary suffixes from tokens. For example, 'jogging', 'jogged', 'jogs' and 'jog' will all become 'jog' after the stemming process, since the suffixes will all be removed from the 'stem' of each word.
33. What is LexRank?
Answer: LexRank is an unsupervised learning method of Text Summarization, based on graph-based centrality scoring of sentences. Essentially, if one sentence happens to be similar to other sentences, the sentence is likely important in the context of the source material. Thus, in order for a sentence to get ranked highly and be included in a summary, it must be similar to many other sentences that are in turn similar to many other such sentences.
34. What do you understand by LSTM? Where are these networks used?
Answer: Long short-term memory, or LSTM, is a type of neural network architecture that is commonly used in the fields of Artificial Intelligence and Deep Learning. Unlike regular feed-forward neural networks, LSTM also has feedback connections. These networks can process not only singular data points, but also sequences of data, such as text and video. Thus, they are commonly employed in Text Summarization systems as the main encoder and decoder components.
35. What is ROUGE?
Answer: Recall-Oriented Understudy for Gisting Evaluation, or ROUGE, is a set of metrics used to evaluate automatic summarization software in Natural Language Processing (NLP) tasks. These metrics compare software-generated summaries with human-made summaries. Suppose a number of annotators created reference summaries, denoted by 'RSS'. The ROUGE-n score of a candidate summary is computed as follows:
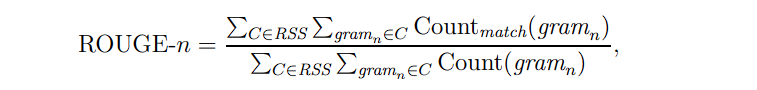
where Countmatch(gramn) is the maximum number of n-grams that co-occur in a candidate summary and a reference summary and Count(gramn) is the number of n-grams in the reference summary.
36. What do you understand by the term 'attention' in the context of Natural Language Processing?
Answer: Attention is a mechanism that makes it possible for a model to contextualize each word in a given sentence, thus giving it a clearer picture of the source material. Attention based models are commonly used for Natural Language Processing (NLP) tasks such as machine translation and text summarization. This is something that the model can learn with the help of training data. By looking at a large number of examples of written text, the model can start to learn about the interdependency of words, the different rules of grammar and punctuation, and more such linguistic details.
37. What do you understand by the term 'self-attention' in the context of Natural Language Processing?
Answer: Traditional Attention is something that was used in combination with Recurrent Neural Networks (RNNs) in order to improve their performance while carrying out Natural Language Processing (NLP) tasks. Self-Attention, on the other hand, was introduced as a replacement to RNNs entirely. Instead of RNNs being used in the encoder and decoder networks, Attention methods were adopted instead, and these methods happen to be much faster overall.
38. What do you understand by the term 'Latent Semantic Analysis'?
Answer: Latent Semantic Analysis (or LSA) is a technique that is used to extract the hidden dimensions of the semantic representation of terms, sentences, or documents, on the basis of their contextual use. In other words, it is a technique of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. The goal is to identify the most important topics from the source text and then to choose the sentences with the greatest combined weights across the topics.
39. What do you understand by the term 'text cohesion' and what are some methods that are used in order to determine cohesive relations between terms?
Answer: Extractive Summarization methods can sometimes fail to capture relationships between different concepts in a text. Anaphoric expressions that refer to some previously expressed word, phrase or meaning (typically pronouns, such as he, him, she and her), need their antecedents in order to be understood. The summary can become difficult to understand if it contains an anaphoric link without its previous contextual definition. Text cohesion refers to the relations between expressions which determine text connectivity. Cohesive properties of the text have been explored by different summarization approaches. Some such approaches are:
- Lexical Chains
- Co-reference Resolution Systems
40. What are 'lexical chains' and how can they be used in Text Summarization?
Answer: Lexical chains represent the cohesion among an arbitrary number of related words. Lexical chains can be recognized by identifying sets of words that are semantically related. Using lexical chains in text summarization is efficient, because these relations are easily identifiable within the source text, and vast knowledge bases are not necessary for computation. By using lexical chains, we can statistically find the most important concepts by looking at their structures in the document rather than deep semantic meaning. All that is required to calculate these is a generic knowledge base that contains nouns and their associations.
41. What is Co-reference Resolution?
Answer: Co-reference Resolution is the process of determining whether two expressions in natural language represent the same entity in the real world. Sentences containing such frequently mentioned objects are then considered a part of the summary.
42. What do you understand by Rhetorical Structure Theory?
Answer: Rhetorical Structure Theory, or RST, is a theory that provides a framework for the analysis of text. It consists of a number of rhetorical relations that tie together text units. The relations connect together a nucleus (which happens to be central to the writer's goal) and a satellite (which is less central material). Finally, a tree-like representation is composed. Then, these text units need to be extracted in order to obtain a summary.
43. How are graph based approaches used to summarize text?
Answer: Each sentence in the source material is represented by a vertex in a graph. Inter-connections between sentences can then be represented by edges between corresponding vertices. These connections are defined using a similarity relation, where similarity is measured as a function of content overlap. The amount of overlap between sentences can be determined by the number of common tokens between the lexical representations of two sentences. Once the ranking algorithm is run on the graph, the sentences are ranked in the descending order of their scores, and the top scoring sentences are included in the summary.
44. Name a few real world graph based algorithms.
Answer: Some real world examples of graph based algorithms are:
- Hyperlink-Induced Topic Search (HITS) - A link analysis algorithm that rates web pages.
- Google's PageRank - An algorithm used to rank web pages in Google's search engine results.
- TextRank - A graph-based ranking model for text processing which can be used in order to find the most relevant sentences (as well as keywords) in a piece of text.
45. What are some of the text editing operations that are performed on pieces of text in order to obtain a concise, abstract summary?
Answer: Some such operations are:
- Sentence Reduction
- Sentence Combination
- Syntactic Transformation
- Lexical Paraphrasing,
- Generalization and Specification
- Reordering
46. What are some measures that can be used to determine the quality of a piece of text?
Answer: Listed below are some such parameters:
- Grammaticality – The text should not contain non-textual items, punctuation errors or incorrect words.
- Non-Redundancy – The text should not contain redundant information.
- Reference Clarity – The nouns and pronouns should be clearly referred to in the
summary. For example, the pronoun he has to mean somebody in the context of the summary. This relates to a previously discussed concept, text cohesion. - Coherence and Structure – the summary should have good structure and the
sentences should be coherent.
47. What do you understand by the terms 'precision' and 'recall' in the context of Text Summarization?
Answer: Precision and Recall are evaluation metrics of co-selection. In the context of Text Summarization, Precision (P) is the number of sentences that occur in both the system and ideal summaries divided by the number of sentences in the system summary, whereas Recall (R) is the number of sentences that occur in both the system and ideal summaries divided by the number of sentences in the ideal summary.
48. What is 'F-score'?
Answer: F-score is another evaluation metric of co-selection, which combines the use of precision as well as recall. It is calculated by finding the harmonic mean of precision and recall.
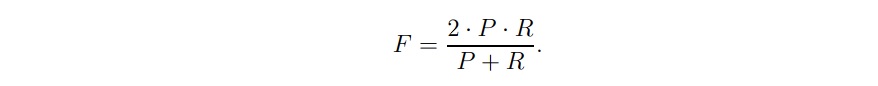
49. Are there any drawbacks to using precision and recall as our evaluation parameters? If so, what can we do to tackle them?
Answer: The main problem with using precision and recall as our evaluation parameters is that it is possible for two systems to produce equally good summaries but for one of them to be ranked much higher than the other. This is because they do not paint a very clear picture of what the most important sentences in a document really are.
To address this issue, the 'relative utility (RU)' measure was introduced. With RU, the model summary represents all sentences of the input document with confidence values for their inclusion in the summary. To compute relative utility, a number of judges are asked to assign utility scores to all n sentences in a document. The top e sentences according to utility score are then called a sentence extract of size e. RU can be mathematically defined as follows:
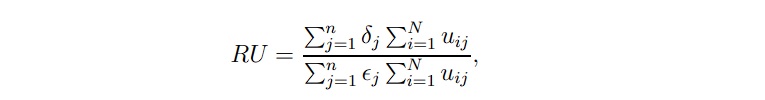
50. What are 'content-based' similarity measures? How do they differ from co-selection?
Answer: It is possible for two sentence to be phrased differently but to mean the same thing. Co-selection measures do not count such sentences as equal. Content-based similarity measures, however, do.
For example, if we have the following two statements (A and B):
A - He went vacationing in Germany.
B - Germany is where he went on a vacation.
It is clear that these statements mean the same thing, however, co-selection measures would not count them as a match, whereas content-based measures would.
Some content-based similarity measures are:
- Cosine Similarity
- Unit Overlap
- Longest Common Subsequence (LCS)
51. What is Cosine Similarity in the context of system evaluation?
Answer: Cosine Similarity is a basic content-based similarity measure. It can be mathematically defined as:
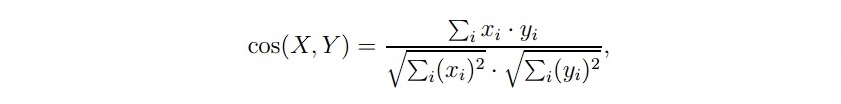
Here, X and Y are representations of a system summary and its reference document based on the vector space model.
52. What is Unit Overlap in the context of system evaluation?
Answer: Unit Overlap is another content-based similarity measure. It can be mathematically defined as:
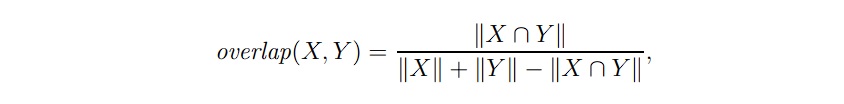
Here, X and Y are representations based on sets of words. ||X|| represents the
size of set X.
53. What is Longest Common Subsequence (LCS) in the context of system evaluation?
Answer: Longest Common Subsequence, or LCS, is also a content-based similarity measure, and is mathematically defined as:
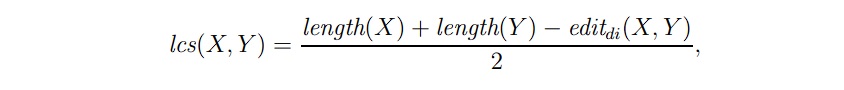
Here, X and Y are representations based on sets of words, lcs(X,Y) is the measure of the longest common subsequence between X and Y, length(X) is the length of the string X, and editdi(X, Y) is the edit distance of X and Y.
54. Briefly explain the 'pyramid method' of evaluation.
Answer: The Pyramid method is a semi-automatic method for summarization evaluation and it was developed in an attempt to address a key problem in summarization: the fact that different humans choose different content when writing summaries. The pyramid method tackles this problem by using multiple human-made summaries, thus exploiting the frequency of information in the human-made summaries in order to assign importance to different facts. At the top of the pyramid there are summarization content units that appear in most of the summaries and thus they have the greatest weight. The lower in the pyramid the summarization content unit appears, the lower its weight is, as it is present in a smaller number of summaries.
55. What are 'task-based' evaluation methods?
Answer: Task-based evaluation methods for Natural Language Process based systems focus on evaluating whether a particular task is achieved, instead of evaluating the system's overall performance. Some such tasks are:
- Document Categorization
- Information Retrieval
- Question Answering
56. What are some real life use cases of Document Categorization?
Answer: Document Categorization, which focuses on assigning categories to documents in order to make them easier to manage, has many applications in the real world, such as:
- Spam Detection
- Sentiment Analysis to categorize Feedback/Opinions
- Support Ticket Categorization
- Visual Classification using Computer Vision
57. How does Information Retrieval reveal the quality of summaries?
Answer: Information Retrieval uses relevance correlation to assess the relative drop in retrieval performance when we go from the source material to the software-generated summary. If the summary is informative, then there will not be a noticeable drop in retrieval performance, whereas if it happens to contain redundant or unimportant sentences, then there will be a noticeable drop in retrieval performance.
58. How is Question Answering used as an extrinsic evaluation metric?
Answer: Question Answering is used mostly in the field of reading comprehension. A source document is summarized with the help of a Text Summarization system, and a set of questions based on the central themes that are described by the source document are manually constructed. The ability of the summary to answer these questions is then evaluated.
59. In what sort of situations are Generic Summarization methods simply not applicable?
Answer: Generic Summarization methods work very well if we do not want to make many assumptions about the domain of the summary, the target audience, or the goal of producing the summary. If, however, we want to summarize a piece of text that belongs to a highly specialized domain, such as medicine, wherein we absolutely cannot skip any details that might be important, Generic Summarization methods are simply not applicable. Domain specific methods need to be employed in such situations, and in the above case, we could use Medical Summarization. In the medical domain, there are massive banks of information and resources that can shed light on millions of highly specific concepts.
60. Compare the efficiency of task-based evaluation methods with intrinsic evaluation methods.
Answer: Task-based evaluation methods happen to be time-consuming and expensive. As a result, they are not particularly suitable for system comparisons during development. Intrinsic evaluations are normally employed in such cases, often through the comparison of summaries with human-made gold standards. When comparisons with gold standards are involved, it is desirable for them to be done automatically, such that the level of human involvement can be kept at a minimum.
61. What do you know about 'TAS' in Journal Summarization?
Answer: 'Technical Article Summarizer', or TAS, generates summaries for a set of documents retrieved as relevant to a user query. Thus, TAS also falls into the category of query-focused as well as multi-document summarization. Rather than using sentence extraction, TAS extracts information from sub-sentential units to fill in pre-defined templates and orders it before generating summary sentences. These summaries are briefings that contain results reported in clinical studies.
62. While we know that individual emails can be summarized, is it possible to create a system that can summarize entire mailboxes that contain not only standalone emails, but also long email threads?
Answer: It is possible to create a system that can summarize entire mailboxes. Newman and Blitzer presented a system capable of accomplishing this task. They first clustered all email in topically related threads. An overview as well as a full-length summary were then generated for each such cluster. The final set of summaries could then be presented as a browsing page. This is commonly seen in news summarization systems.
63. How would you categorize 'Latent Semantic Analysis' based measures in the list of system evaluation metrics?
Answer: Latent Semantic Analysis (LSA) based measures can be categorized as intrinsic content evaluation measures that happen to be content-based, since they are not based on the principle of co-selection.
64. What are n-grams?
Answer: N-grams are contiguous sequences of n items from a given text or speech corpus, commonly used in the fields of computational linguistics and probability. The items can be syllables, words or letters depending on the application. Using n-grams along with the probabilities of the occurrence of certain words in a given sequence can improve the functionality of automatic systems.
65. How can we exploit citation links between different research papers to aid Text Summarization?
Answer: Often, when one research paper references another one, it either contains a concise summary of the cited paper, or important information pertaining to the cited paper. Thus, we can exploit these links between research papers by generating a single summary in a way such that the inputs to the summarizer are the sentences from other research papers in which a particular research paper is cited.
66. What is Impact Summarization?
Answer: Impact Summarization is used to summarize research papers, and can be formally defined as - "The task of extracting sentences from a paper that represent the most influential content of that paper." In order for a summary to be generated, other research papers containing citations to a particular research paper (in a large collection of research papers) are found, and the areas where the citations occur are extracted.
67. When is the use of systems for automatic sentence segmentation necessary?
Answer: When dealing with speech summarization, the use of systems for automatic sentence segmentation is necessary when we do not have access to human transcripts of the input. In many cases, we might find the need to additionally tune the sentence segmentation system.
68. When do LSA based measures work better and when do ROUGE based measures work better?
Answer: Based on the works of various researchers, the system ranking provided by ROUGE works well when we compare summaries with abstracts. LSA based measures, on the other hand, work well when we compare summaries with full texts (source material/original documents).
69. What is the 'granularity problem'?
Answer: The granularity problem is another drawback of using precision and recall as our evaluation metrics. It arises because sentences are not the best granularity for measuring content. Sentences can differ in many ways, such as word length and the amount of information that they convey. Choosing a longer, more informative sentence is of more use than selecting a shorter sentence. It is possible for two summaries to have the exact same precision and recall scores, but for them to not be equally informative.
70. Where do you think the future of Summarization systems lies?
Answer: With the huge surge in the number of people who have access to the internet in this day and age, the type of Summarization that is of practical interest is seeing change. Summarization has recently been paired with work done on sentiment analysis. An example of this is summaries that list the pros and cons of a particular service or product. They can group together similar opinions and present the ones that might be of most use to an outsider.
Another area of interest is social media, which has also seen a step rise in the number of users in recent times. Summarization in such cases may be useful in navigating a network and producing shortened versions of a person's recent activity. Most people who use social media now communicate differently, using abbreviations and text slang, that summarizers are not typically used to dealing with. More work is being done in these areas, and future summarizers will be able to work with this new age textual information.
71. What is the observation that motivated the design of the SumBasic algorithm?
Answer: SumBasic is an algorithm that generates multi-document summaries, inspired by the observation that words that occur frequently in a cluster of documents have a higher probability of appearing in human-made summaries as compared to words that do not occur as frequently.
72. Mention the steps involved in the SumBasic algorithm.
Answer: The SumBasic algorithm is as follows:
-
1 Compute the probability distribution over the words wi appearing in the input, p(wi) for every i, or:
p(wi) = n/N -
For each sentence Sj in the input, assign a weight equal to the average probability of the words in the sentence, or:
Sj = p(wi)/|wi| -
Pick the best scoring sentence that contains the word with the highest probability.
-
For each word wi in the sentence chosen at step 3, update their probability.
pnew(wi) = pold(wi)pold(wi) -
Go back to step 2 if the desired summary length has not been reached.
73. What is Kullback-Leibler divergence?
Answer: In the realm of mathematical statistics, the Kullback-Leibler divergence, which is also often termed relative entropy, is a type of statistical distance, that is used to measure how different a probability distribution P is, from a reference probability distribution Q.
74. What is the principle behind the working of the KL Sum algorithm?
Answer: The KL Sum algorithm is a greedy method, that creates a summary by adding sentences to it as long as the Kullback-Leibler divergence (refer to Question 73) is decreasing. This ensures that the summary contains a set of sentences that happen to be similar to the document set unigram distribution.
75. What is Luhn's Heuristic Method for Text Summarization?
Answer: Luhn's Heuristic Method for Text Summarization is one of the first Text Summarization algorithms, being published in 1958. It is based on TF-IDF, and selects words of high importance based on their frequency of occurrence. Also, higher weightage is given to the words that occur at the beginning of the document.
76. What is the Edmunson Heuristic Method for Text Summarization?
Answer: The Edmunson Heuristic Method for Text Summarization, along with Luhn's Heuristic Method for Text Summarization, strongly influenced the future of summarizers. This method in particular, accounted for a few extra details:
- Bonus Words - Words stated by the user as of high importance.
- Stigma Words - Words of low or even negative importance.
- Stop Words - Words that do not tell us anything about the content of the source material, i.e: function words.
Moreover, Edmunson also suggested that we can consider words in the document's title as bonus words.
77. What is the BERT model? Where is it used?
Answer: Bidirectional Encoder Representations from Transformers, or BERT, is a system that is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. The BERT model was pretrained on two tasks: language modelling and next sentence prediction, and as a result of the training process, BERT learns contextual embeddings for words. After this pretraining process, which happens to be very computationally expensive, the BERT model can be fine tuned with much fewer resources in order to perform a variety of Natural Language Processing (NLP) tasks such as question answering, sentiment analysis and general language understanding.
With this article, you should now have a solid understanding of most Text Summarization based concepts. Thanks for reading!