
Get this book -> Problems on Array: For Interviews and Competitive Programming
In this article, we will go over various questions that cover the fundamentals and inner workings of the BERT model.
1. Briefly explain what the BERT model is.
Answer: BERT, which stands for Bidirectional Encoder Representations from Transformers, is a language representation model that aims at tackling various NLP tasks, such as question answering, language inference, and text summarization.
2. How is the BERT model different from other language representation models?
Answer: The BERT model pretrains deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. The BERT model is pretrained on two relatively generic tasks, Masked Language Modelling (MLM), and Next Sentence Prediction. After the pretraining process, which happens to be very computationally expensive, the BERT model can be fine tuned with much fewer resources (just one extra output layer) in order to create state-of-the-art models that are fit to tackle a variety of NLP tasks, which is not often seen in other language representation models.
3. How do BERT's results on different NLP tasks compare to those of the best models that came before it?
Answer: BERT obtains state-of-the-art results on eleven different NLP tasks, and in some areas, produces not just incrementally, but significantly better results. For example, it pushes the GLUE score to 80.5%, which is a massive 7.7% absolute improvement when compared to previous state-of-the-art models.
4. What are downstream tasks in the context of NLP?
Answer: In NLP, downstream tasks represent the problem that we actually wish to solve. This is noteworthy since a lot of steps in NLP tasks, such as the pretraining of models using general data, do not necessarily represent the problem that we wish to solve. The pretraining phase simply allows our model to learn. The fine-tuning phase, where we use relevant data on our pre-trained model in order to obtain meaningful results, is an example of a downstream task.
5. What are the two existing strategies for applying pre-trained language representations to downstream tasks?
Answer: The two strategies for applying pre-trained language representations to downstream tasks are: fine-tuning, and feature extraction. In fine-tuning, we take a pretrained model and update all of the model's parameters in order for it to be able to perform the task that we want it to. The feature extraction approach uses task-specific architectures that include the pre-trained representations as additional features.
6. How is BERT pretrained?
Answer: BERT is pretrained on Masked Language Modelling (MLM) and Next Sentence Prediction. The masked language model randomly masks some of the tokens from the input, and our objective is to accurately predict what these masked tokens are, based only on their context. This rids us of the unidirectionality constraint, as the MLM objective enables the representation to fuse the left and the right context, which allows us to pretrain a deep bidirectional transformer. The Next Sentence Prediction task trains our model to predict whether or not a sentence comes after another sentence by studying the longer-term dependencies between sentences.
7. What are context-free models?
Answer: Context-free models, such as GloVe, generate a single word embedding representation for each word in the vocabulary. This means that certain words that have multiple meanings, will have the same inherent representation in very different sentences. For example, 'parks' will have the same context-free representation in 'he parks his car' and 'she likes going to water parks'.
8. What are contextual models?
Answer: Contextual models generate a representation of each word based on the all of the surrounding words in a sentence. This has many implications, one of which makes it possible for words that have multiple meanings, or homonyms, to be consistently interpreted correctly in contextual models, since the model interprets each word based on the context of its use.
9. What are the different types of contextual models? Is BERT a contextual model or a context-free model?
Answer: The different types of contextual models are:
- Unidirectional Contextual Models
- Bidirectional Contextual Models.
Unidirectional Contextual Models represent words based on all of their previous context. This means that each word is contextualized with respect to only the words before it, and not after it.
For example:
If we consider the sentence- 'he went to the bank to withdraw money', the word 'bank' is contextualized based on the sequence of words- 'he went to the', and not 'to withdraw money'. As we can see, this can lead to important information being omitted. Bidirectional Contextual Models, however, tackle this issue by contextualizing words with respect to their previous context as well as next context. Thus, if we consider the above sentence once again, a Bidirectional Contexteual Model would represent 'bank' based on 'he went to the....to withdraw money'.
BERT is a Bidirectional Contextual Model, and this is why it is considered a deeply bidirectional model.
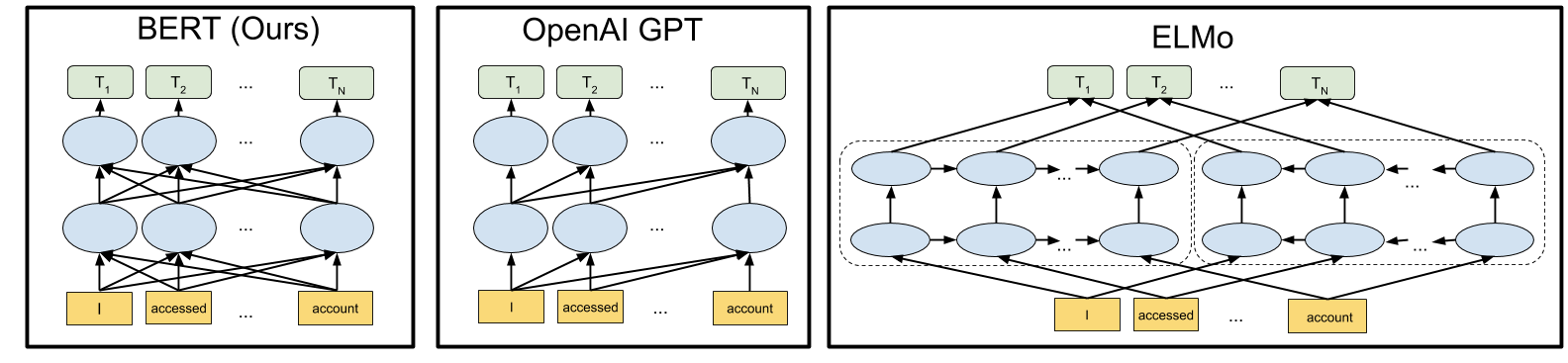
10. What are Transformers?
Answer: Transformers are a type of neural network architecture. They avoid using the principle of recurrence, and work entirely on an attention mechanism to draw global dependencies between the input and the output. Transformers allow for much more parallelization than sequential models, and can achieve very high translation quality even after being trained only for short periods of time. They can also be trained on very large amounts of data without as much difficulty. Transformer models, such as BERT, are used for various Natural Language Processing (NLP) tasks, such as paraphrasing, summarization, and abstractive question answering.
11. What is Self-Attention in the context of Transformers?
Answer: Traditional Attention is something that was used in combination with Recurrent Neural Networks (RNNs) in order to improve their performance while carrying out Natural Language Processing (NLP) tasks. Self-Attention, on the other hand, was introduced as a replacement to RNNs entirely. Instead of RNNs being used in the encoder and decoder networks, Attention methods were adopted instead, and these methods happen to be much faster overall.
12. Highlight the properties of a Transformer's encoder and decoder.
Answer: Encoders are Bidirectional Self-Attentive models. This means that each token in a sentence is attended to after taking into consideration all of its surrounding tokens.
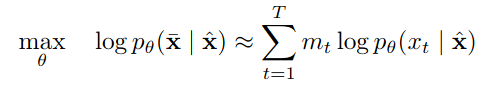
Decoders, on the other hand, are Unidirectional Self-Attentive models. Here, only the tokens that appear before a particular token are considered while attending to that token.
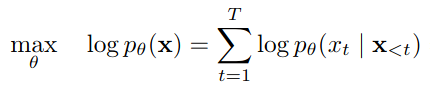
13. What part of BERT's architecture gives it Bidirectionality?
Answer: The Transformer Encoder, which is a Bidirectional Self-Attentive model, gives BERT its Bidirectionality. This is because every token in a sentence is attended to after considering its context with respect to every other token in that sentence.
14. What is BART? How is it different from BERT?
Answer: Bidirectional Auto Regressive Transformer, or BART, is a sequence-to-sequence de-noising auto encoder. Its architecture comprises of a Bidirectional Encoder (such as in BERT), which uses more complicated masking mechanisms during the pretraining phase, as opposed to BERT's simpler token masking approach. It also uses an Auto Regressive decoder (such as in the GPT-2 model).
15. Explain the Masked Language Model (MLM) task.
Answer: Masked Language Model (MLM) represents the task of inputting a sentence to our model, such that it can optimize its weights and output the same sentence. The only catch is that we mask some of the tokens in the sentence. This process allows BERT to contextualize the remaining words in the sentence to try and uncover the mask, essentially filling the blank. This task improves the model's ability to comprehend the style and stylistic patterns of the language being used.
16. Explain the Next Sentence Prediction (NSP) task.
Answer: Next Sentence Prediction (NSP) involves giving BERT two sentences, say sentence 1 and sentence 2, and asking it whether sentence 2 comes after sentence 1. If the two sentences have very few logical similarities, then sentence 2 will most likely not follow sentence 1. MLM and NSL are the two tasks that BERT is trained on.
17. Which BERT process is more computationally expensive: pretraining or fine tuning?
Answer: Compared to pretraining, fine tuning is relatively inexpensive, as the transformer's self attention mechanism allows for BERT to model many downstream tasks. The entire process can take place in as little as a few hours on a standard GPU.
18. Briefly discuss the text corpora that were used to pretrain BERT.
Answer: BooksCorpus, which contains close to 800 million words, and the English Wikipedia, which contains over 3 billion words, were used to pretrain BERT. These corpora were chosen because they contain long and contiguous sentences, as opposed to shuffled sentences.
19. What is Natural Language Understanding (NLU)?
Answer: Natural Language Understanding (NLU) is a domain of Artificial Intelligence and Machine Learning that makes it possible for software systems to comprehend input (text or speech) in the form of sentences. This allows for humans to interact with computers without needing to use formalized syntaxes.
20. What is GLUE in the context of BERT?
Answer: General Language Understanding Evaluation (GLUE), is a collection of a broad range of Natural Language Understanding (NLU) tasks. Models such as BERT are evaluated on these tasks in order to determine how well they perform in different scenarios. BERT performs remarkably well in these tasks.
21. What are some GLUE tasks?
Answer: Some GLUE tasks are-
- CoLA (Corpus of Linguistic Acceptability): Determining whether or not a sentence is gramatically correct.
- SST-2 (Stanford Sentiment Treebank): Predicting the sentiment of a sentence.
- MRPC (Microsoft Research Paraphrase Corpus): Determining whether or not two sentences are semantically equivalent.
- QQP (Quora Question Pairs2): Determining whether or not two questions are semantically equivalent.
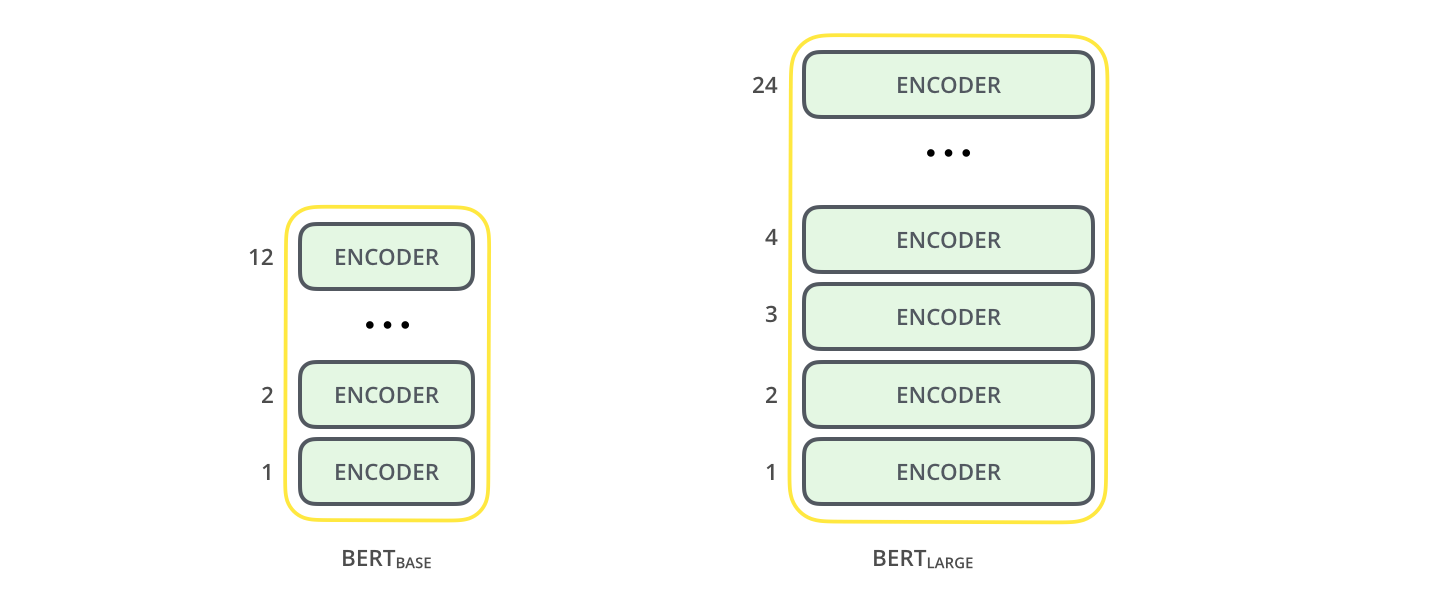
22. What is the difference between BERT Base and BERT Large?
Answer: The difference between BERT Base and BERT Large lies in the number of encoder layers that they possess. BERT Base contains 12 encoder layers stacked one on top of the other, whereas BERT Large contains 24 encoder layers stacked one on top of the other. This difference makes BERT Large the better performer, but it also the need for more computational power as well as memory.
23. What is RoBERTa?
Answer: A Robustly Optimized BERT Pretraining Approach, or RoBERTa, was worked on by Facebook AI and is a slightly modified version of BERT with better optimization for pretraining. While RoBERTa's architecture is almost the same as BERT's architecture, a few notable changes are as follows:
- The Next Sentence Prediction (NSP) objective was removed from consideration, since the original paper's authors observed equal or slightly better performance on downstram tasks with the NSP loss removed.
- The authors trained the model with bigger batch sizes and longer sequences, which aids the Masked Language Modelling objective, leading to better end-task accuracy.
- Instead of obtaining a single static mask during the preprocessing of data (BERT), the data is duplicated and masked on ten different occassions, with different masking patterns on each occassion over multiple epochs.
- Aside from the English Wikipedia and BooksCorpus, additional datasets were used to pretrain RoBERTa. In total, RoBERTa was pretrained on 160 gigabytes of uncompressed text!
All of these changes brought about an increase in overall performance and efficiency.
24. What is Knowledge Distillation?
Answer: Knowledge Distillation is the process of training a smaller model to replicate the results produced by a much larger model. This is done to reduce pretraining time.
25. What is DistilBERT?
Answer: DistilBERT is a compressed (or distilled) version of BERT, that performs very similarly to BERT Base (95% of the performance is retained when evaluated using GLUE), but has HALF as many parameters. A few techniques that were used to pretrain RoBERTa (such as removing the NSP objective and using much larger batch sizes/sequences) are also used to pretrain DistilBERT, thus making it all the more efficient. This method of compression can be applied to other models, such as GPT2, as well!
26. What is ALBERT?
Answer: A Lite BERT, or ALBERT, is an upgrade to BERT, which boasts optimized performance with significantly fewer parameters. A few notable changes that were made while designing ALBERT are as follows:
- Most language models, including BERT, have different parameters for different layers. This is not ideal, since it causes the model to learn similar operations at different layers, using different parameters. ALBERT, however, uses parameter sharing. Thus, the same layer is applied one on top of the other. This leads to a slight reduction in accuracy, but also results in a significant decrease in the number of parameters required for ideal functionality.
- While Next Sentence Prediction (NSP) loss was used to pretrain BERT, a more complicated loss measure known as Sentence Order Prediction (SOP), which is based on the coherence of sentences, is used in ALBERT.
- In BERT, the input layer embeddings and the hidden layer embeddings have the same size. In ALBERT, however, the embedding matrix is split in a way such that the input layer has relatively lower dimensionality, and the hidden layer has relatively higher dimensionality. This factorization of the embedding matrix brings about an 80% drop in the number of parameters, with only a small drop in performance.
27. What are some alternatives to BERT that can be used for Natural Language Understanding tasks?
Answer: Some alternatives to BERT are:
- GPT-3 by OpenAI: GPT-3 is a large scale transformer based model, and performs incredibly well at tasks such as translation and question answering. Having been trained on 175 billion parameters, it is over four hundred times bigger than in size than even BERT Large. One major drawback, however, is that while BERT is open sourced, GPT-3 is not.
- Text-To-Text Transfer Transformer (T5): T5 reframes all NLP tasks into a unified format wherein the input and output are always text strings, as opposed to BERT. It excels at various Natural Language Processing (NLP) tasks, such as translation, question answering and classification.
- XLNet: XLNet is an extension of TransformerXL, pretrained using an auto regressive method. This model is particularly good at tasks involving long contexts. Under suitable circumstances, it outperforms BERT in twenty tasks, often by a notable margin.
With this article at OpenGenus, you must have a complete idea of BERT and good practice of Interview Questions.