
Reading time: 35 minutes
Word Representations, a popular concept in Natural Language Processing, are often used to improve the performance characteristics of text classification algorithms. As the name suggests, it is used to represent words with an alternative form which is easier to process and understand.
- An example of word representation includes vector
- It is also known as a word feature
- Some word representations result in low accuracy since rarely occurring words have sparse vectors
- Unsupervised approaches of word representations have begun to gain traction, as they are known to improve accuracy
'Word representations: a simple and general method for semi-supervised learning' is a very resourceful paper on Word Representations, and this article is based on word representations mentioned in the paper.
The different word representations that we will discuss are as follows -
-
Distributional Representations - one of the earliest word representations, with its forms in use since the year 1989, with Sahlgren, a PhD researcher, performing the most recent experiments in 2006.
-
Clustering-based Representations - Distributional representations were first transformed into Clustering-based in the year 1993.
While Brown Clustering was proposed in the year 1992, its use in NLP applications began from 2004. -
Distributed Representations - namely, Collobert and Weston Embeddings (2008), and HLBL Embeddings (2009)
Some Important Terms
-
Named Entity Recognition - is a task in which text data is identified and classified as belonging to either person names, or numerical values, or names of organisations, etc.
-
Chunking - is the process of extracting meaningful parts of a sentence or phrases for Information Extraction purposes.
-
n-gram - a method of assigning probabilities to a sequence of words in data.
Distributional Representations
- These representations are based upon word-word co-occurence matrices built on the vocabulary size of a given text corpus, taking into consideration the context, in terms of the columns in the matrix.
- Words are used to predict other words that co-occur with them.
- The word representations are in the form of vectors in a multi-dimensional space.
- Storing these co-occurence matrices is memory-intensive
- GloVe and word2vec are built upon this concept
Word2Vec
- It uses a 2-layer neural network
- It can work in two ways - one, it can predict with a certain probability, the word most likely to occur if the context is given or two, exactly the reverese, predict the context from a given word
- The output vector generated per word is positioned in a multi-dimensional space such that similar words have vectors occurring together
- This algorithm was developed at Google, led by Tomas Mikolov
GloVe - Global vectors for word representations
- It uses co-occurrence information in the corpus as an additional training feature
- Tabulating the co-occurrence matrix may be computationally intensive for a large corpus
- This algorithm was developed as an open-source project at Stanford University
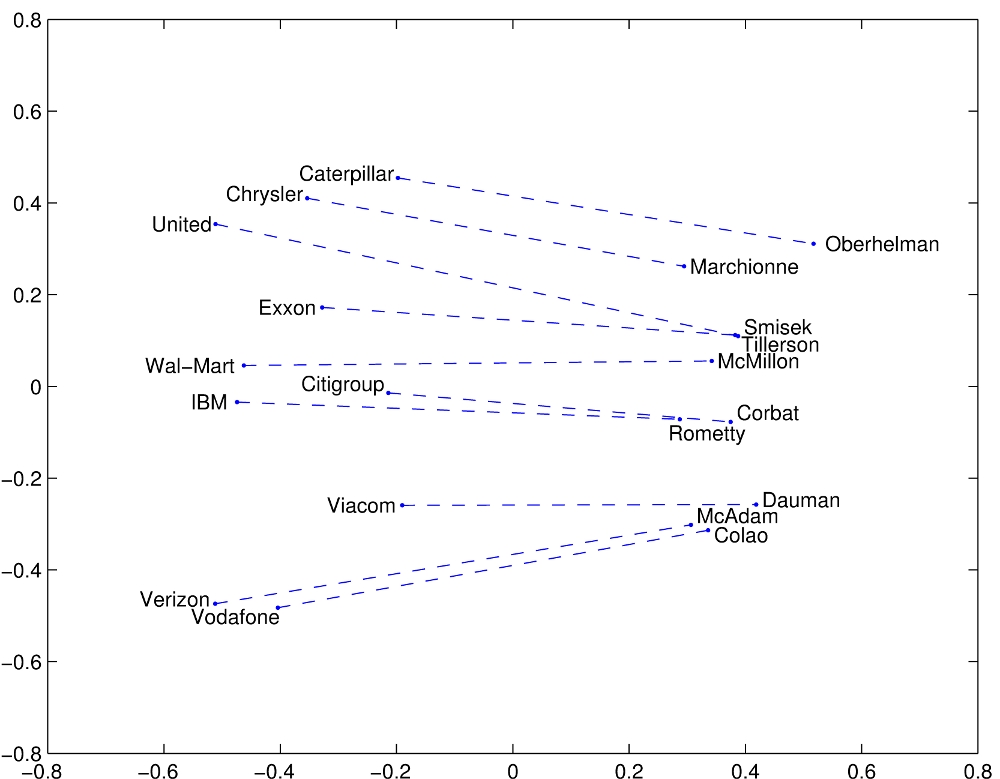
Some examples of co-occurring words in a multi-dimensional space (including the one given below) can be found on Stanford NLP's official website for GloVe
Clustering-based
The most common clustering-based word representation technique is Brown Clustering
Brown Clustering
- It is an unsupervised hierarchical clustering algorithm.
- It creates a binary tree of the words in the data.
- The clustering of words is based on similarity, and words belonging to the same cluster are placed together/nearby in the binary tree.
- Input to the algorithm consists of a corpus and it has a fixed number of output classes. Depending on the vocabulary of the corpus, similar words or items are grouped together in one of the classes.
- Brown Clustering uses bigram approach (a special case of n-gram). Here bigram implies the sequence is of length 2.
- Variations of Brown clustering also exist, one of which includes a method that explores a trigram approach of the algorithm, etc.
An example of Brown Clustering given in the research paper 'Generalised Brown Clustering and Roll-Up Feature Generation' is as follows -

As can be seen, similar words like cats and dogs occur together
Another clustering algorithm which can be used is a k-means-like non-hierarchical clustering for phrases, which uses MapReduce (a popular processing technique with 2 main phases - Map and Reduce - mainly used for big datasets and scalability for large systems)
Distributed Representations
Distributed Representations are also known as word embeddings.
- Word embeddings are most popularly used to train neural network NLP models.
- It is a dense, low-dimensional and compact way of representing information.
- Word embeddings consist of vectors in a multidimensional space
1. Collobert and Weston embeddings
- Collobert and Weston presented the benefits of using pre-trained word embeddings with a corresponding single convolutional neural network model, which is still popularly used in NLP.
- The general steps include mapping words into vectors so that they could be easily processed by the further layers of the neural network.
- Collobert and Weston described the architecture of the neural network as follows - "The first layer extracts features for each word. The second layer extracts features from the sentence treating it as a sequence with local and global structure"
- Collobert and Weston proposed using a Time-Delayed Neural Network to reinforce the idea of a sequence of words having a fixed order.
- This approach can be used to train models over a large vocabulary size, pretty fast, but the disadvantage is in the testing of the models, especially when testing data is large.
2. HLBL embeddings
- HLBL stands for hierarchical log-bilinear model.
- It takes n-gram as an input, learns from embeddings of the first (n - 1) words, and predicts the embedding for the nth word. This technique, performed with an optimization to reduce the number of computations that are performed, resulted in HLBL model.
- While n-gram models are simpler and show good performance characteristics, they do not take into consideration semantic and contextual similarity to train the features.
- HLBL model was first proposed by Mnih and Hinton.
- It has 2 main components - one, a binary tree with words at the leaf nodes, and two, a model for decision-making at the nodes.
- Mnih and Hinton proposed this model with a linear time complexity as compared to the LBL (log bilinear) model which has a quadratic time complexity.
Experimental Analysis
Turian, Ratinov and Bengio performed experimental analysis of introducing word representations to tasks such as Named Entity Recognition and Chunking in the paper mentioned.
Here, I will describe, in brief, some of the processes involved.
Training Data
- For Named Entity Recognition (NER), the training period was several epochs long, stopped only when no changes were observed for 10 epochs
- A specific format was used for dates, and numbers, to allow a high-level abstraction.
- Data Cleaning was performed on unlabeled data by removing sentences which had more than 90% lowercase alphabets. They observed that all word representations performed better in such a case.
- They also provided the hypothesis that training the word representations over a consistently growing vocabulary, rather than cleaned data would provide more accuracy.
Inducing Word Representations
- The word representations were induced over a period of time differing for the different kinds of representations -
- Brown clusters - 3 days
- C&W Embeddings - a few weeks
- HLBL Embeddings - 7 days
- They also observed that the quality of C&W Embeddings kept increasing as training period continued, thus posing the question of defining a stopping condition.
Scaling and Capacity of Word Representations
- The process of scaling (process of shifting the standard deviation by introducing a scale factor) was introduced for the embeddings.
- They found that all embeddings had a standard deviation of 0.1, in the case of similar-shaped curves resulting from scaling.
Note: Capacity controls for Brown Clustering is number of clusters, while that for word embeddings is the number of dimensions.
- They observed that there was no optimal capacity for word representations, moreover the capacity depended on the task.
Conclusion
Some of the conclusions drawn from the results included -
- Different types of word representation features can be combined to obtain improved accuracy for the tasks at hand. This increase is more relevant in case of Named Entity Recognition, than Chunking.
- Brown Clustering yields better accuracy than Collobert and Weston Embeddings, which in turn gives more accuracy than the HLBL embeddings.
- For rare words, in NER, Brown Clustering gives better representations, whereas for Chunking, all representations are comparable.
With this article at OpenGenus, you must have the complete idea of different word representations. Enjoy.
References
- Turian, J., Ratinov, L., & Bengio, Y. (2010, July). Word representations: a simple and general method for semi-supervised learning. In Proceedings of the 48th annual meeting of the association for computational linguistics (pp. 384-394). Association for Computational Linguistics.
- Derczynski, L., Chester, S., & Bøgh, K. S. (2015, January). Tune your brown clustering, please. In International Conference Recent Advances in Natural Language Processing, RANLP (Vol. 2015, pp. 110-117). Association for Computational Linguistics.
- Collobert, R., & Weston, J. (2008, July). A unified architecture for natural language processing: Deep neural networks with multitask learning. In Proceedings of the 25th international conference on Machine learning (pp. 160-167).
- Lucy, L., & Gauthier, J. (2017). Are distributional representations ready for the real world? Evaluating word vectors for grounded perceptual meaning. arXiv preprint arXiv:1705.11168.
- Derczynski, L., & Chester, S. (2016, February). Generalised Brown clustering and roll-up feature generation. In Thirtieth AAAI Conference on Artificial Intelligence.
- Mnih, A., & Hinton, G. E. (2009). A scalable hierarchical distributed language model. In Advances in neural information processing systems (pp. 1081-1088).