
YOLO is a state of the art, real-time object detection algorithm created by Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi in 2015 and was pre-trained on the COCO dataset. It uses a single neural network to process an entire image. The image is divided into regions and the algorithm predicts probabilities and bounding boxes for each region.
YOLO is well-known for its speed and accuracy and it has been used in many applications like: healthcare, security surveillance and self-driving cars. Since 2015 the Ultralytics team has been working on improving this model and many versions since then have been released. In this article we will take a look at the fifth version of this algorithm YOLOv5.
Table of content
- High-level architecture for single-stage object detectors
- YOLOv5 Architecture
- Activation Function
- Loss Function
- Other improvements
- YOLOv5 vs YOLOv4
- Conclusion
1. High-level architecture for single-stage object detectors
There are two types of object detection models : two-stage object detectors and single-stage object detectors. Single-stage object detectors (like YOLO ) architecture are composed of three components: Backbone, Neck and a Head to make dense predictions as shown in the figure bellow.
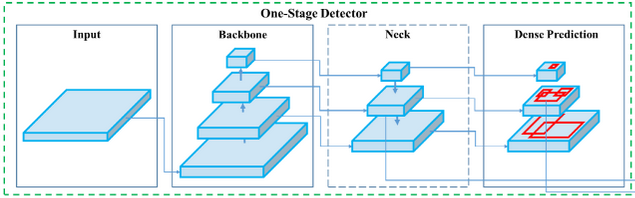
Model Backbone
The backbone is a pre-trained network used to extract rich feature representation for images. This helps reducing the spatial resolution of the image and increasing its feature (channel) resolution.
Model Neck
The model neck is used to extract feature pyramids. This helps the model to generalize well to objects on different sizes and scales.
Model Head
The model head is used to perform the final stage operations. It applies anchor boxes on feature maps and render the final output: classes , objectness scores and bounding boxes.
2. YOLOv5 Architecture
Up to the day of writing this article, there is no research paper that was published for YOLO v5 as mentioned here, hence the illustrations used bellow are unofficial and serve only for explanation purposes.
It is also good to mention that YOLOv5 was released with five different sizes:
- n for extra small (nano) size model.
- s for small size model.
- m for medium size model.
- l for large size model
- x for extra large size model
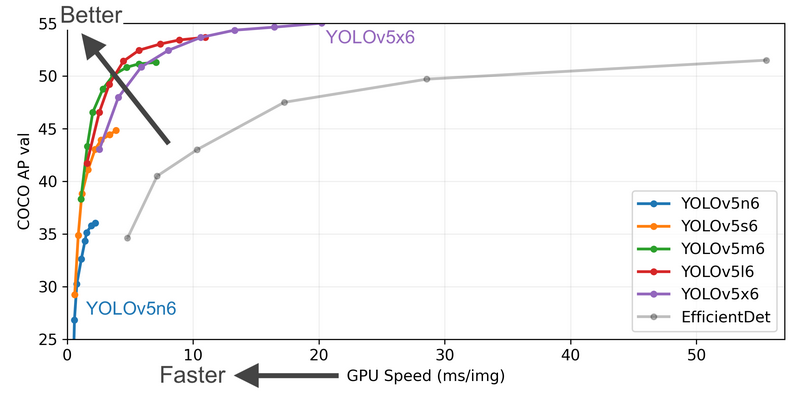
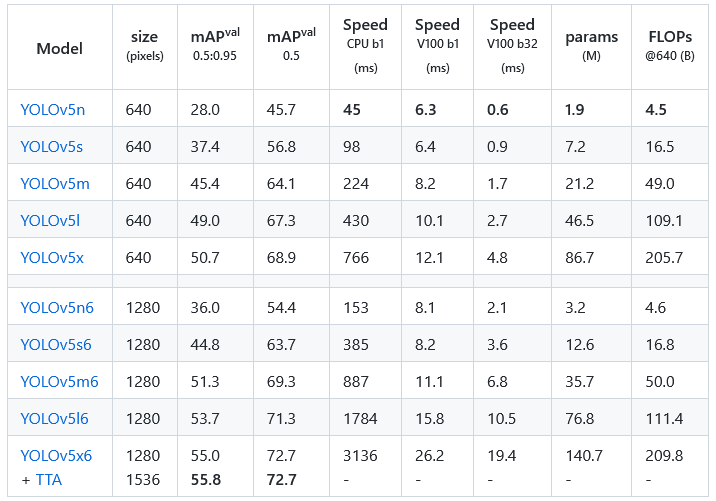
There is no difference between the five models in terms of operations used except for the number of layers and parameters as shown in the table below.
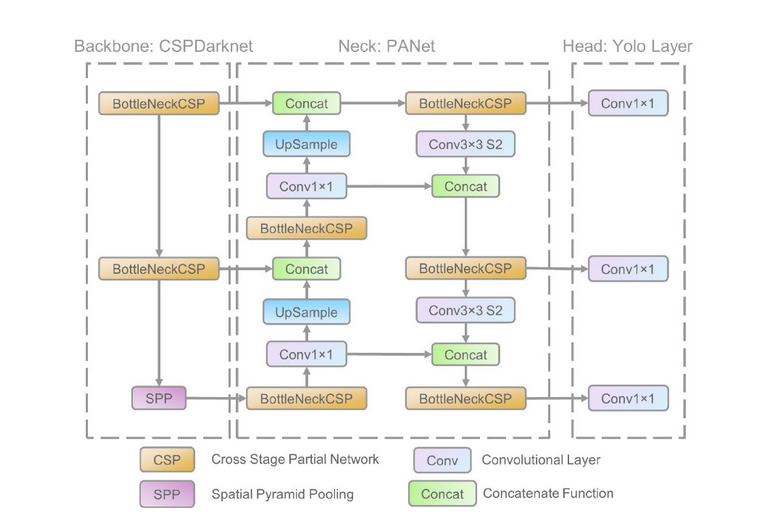
All the YOLOv5 models are composed of the same 3 components: CSP-Darknet53 as a backbone, SPP and PANet in the model neck and the head used in YOLOv4.
CSP-Darknet53
YOLOv5 uses CSP-Darknet53 as its backbone. CSP-Darknet53 is just the convolutional network Darknet53 used as the backbone for YOLOv3 to which the authors applied the Cross Stage Partial (CSP) network strategy.
Cross Stage Partial Network
YOLO is a deep network, it uses residual and dense blocks in order to enable the flow of information to the deepest layers and to overcome the vanishing gradient problem. However one of the perks of using dense and residual blocks is the problem of redundant gradients. CSPNet helps tackling this problem by truncating the gradient flow. According to the authors of [3] :
CSP network preserves the advantage of DenseNet's feature reuse characteristics and helps reducing the excessive amount of redundant gradient information by truncating the gradient flow.
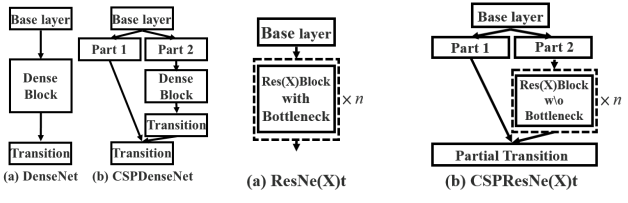
YOLOv5 employs CSPNet strategy to partition the feature map of the base layer into two parts and then merges them through a cross-stage hierarchy as shown in the figure bellow
Applying this strategy comes with big advantages to YOLOv5, since it helps reducing the number of parameters and helps reducing an important amount of computation (less FLOPS) which lead to increasing the inference speed that is crucial parameter in real-time object detection models.
Neck of YOLOv5
YOLOv5 brought two major changes to the model neck. First a variant of Spatial Pyramid Pooling (SPP) has been used, and the Path Aggregation Network (PANet) has been modified by incorporating the BottleNeckCSP in its architecture.
Path Aggregation Network (PANet)
PANet is a feature pyramid network, it has been used in previous version of YOLO (YOLOv4) to improve information flow and to help in the proper localization of pixels in the task of mask prediction. In YOLOv5 this network has been modified by applying the CSPNet strategy to it as shown in the network's architecture figure.
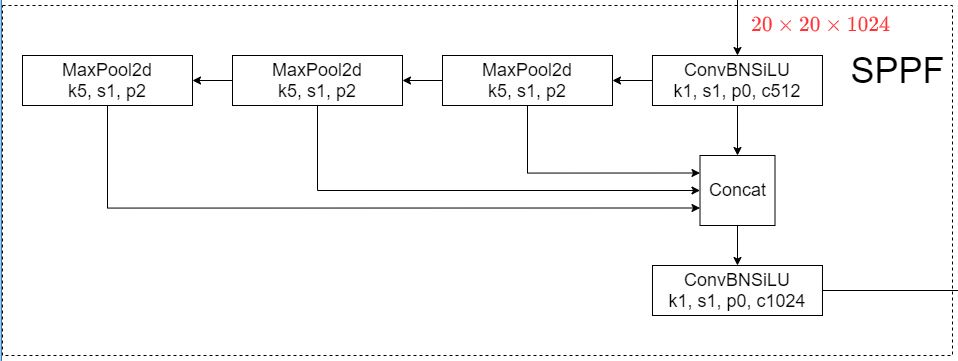
Spatial Pyramid Pooling (SPP)
SPP block [4] performs an aggregation of the information that receives from the inputs and returns a fixed length output. Thus it has the advantage of significantly increasing the receptive field and segregating the most relevant context features without lowering the speed of the network. This block has been used in previous versions of YOLO (yolov3 and yolov4) to separate the most important features from the backbone, however in YOLOv5(6.0/6.1) SPPF has been used , which is just another variant of the SPP block, to improve the speed of the network
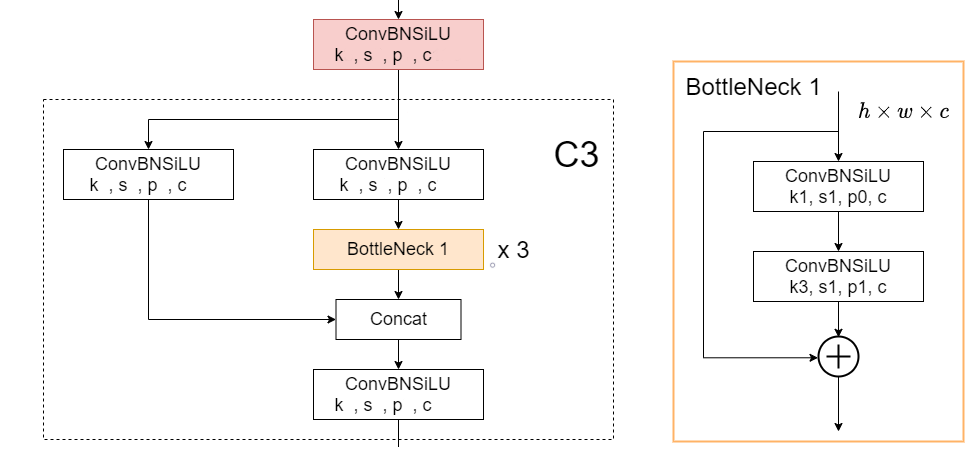
Head of the network
YOLOv5 uses the same head as YOLOv3 and YOLOv4. It is composed from three convolution layers that predicts the location of the bounding boxes (x,y,height,width), the scores and the objects classes.
The equation to compute the target coordinates for the bounding boxes have changed from previous versions, the difference is shown in the figure bellow.
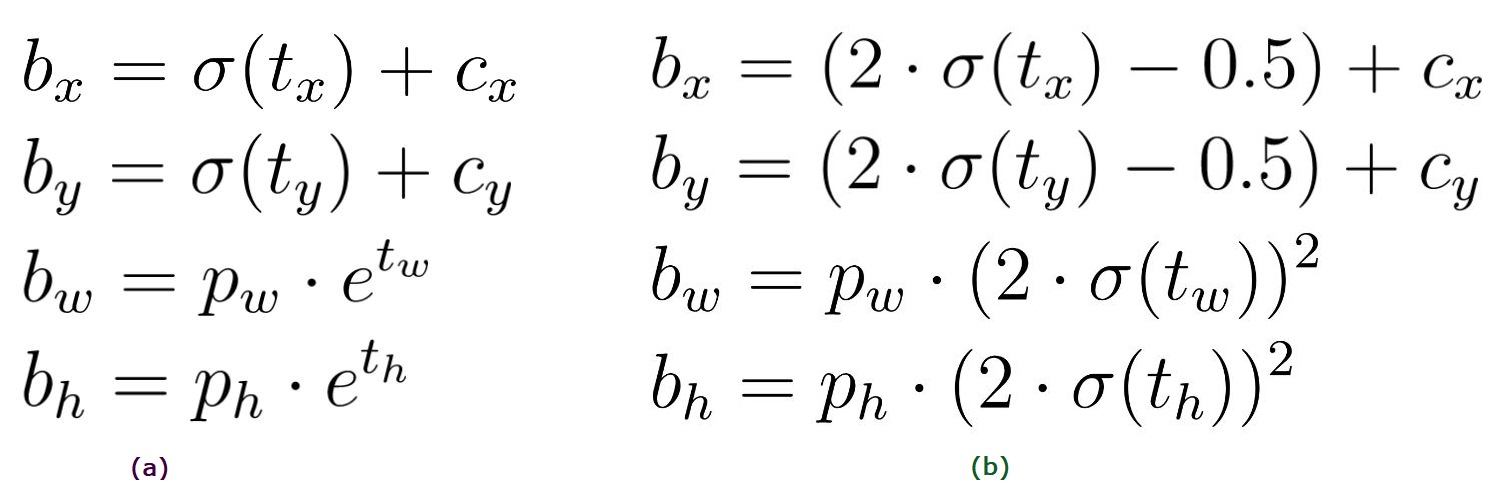
3. Activation Function
Choosing an activation function is crucial for any deep learning model, for YOLOv5 the authors went with SiLU and Sigmoid activation function.
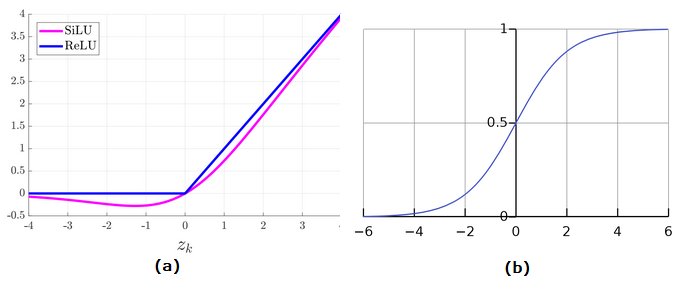
SiLU stands for Sigmoid Linear Unit and it is also called the swish activation function. It has been used with the convolution operations in the hidden layers. While the Sigmoid activation function has been used with the convolution operations in the output layer.
4. Loss Function
YOLOv5 returns three outputs: the classes of the detected objects, their bounding boxes and the objectness scores. Thus, it uses BCE (Binary Cross Entropy) to compute the classes loss and the objectness loss. While CIoU (Complete Intersection over Union) loss to compute the location loss. The formula for the final loss is given by the following equation
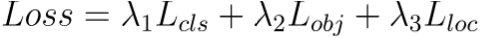
5. Other improvements
In addition to what have been stated above, there are still some minor improvements that have been added to YOLOv5 and that are worth mentioning
- The Focus Layer : replaced the three first layers of the network. It helped reducing the number of parameters, the number of FLOPS and the CUDA memory while improving the speed of the forward and backward passes with minor effects on the mAP (mean Average Precision).
- Eliminating Grid Sensitivity: It was hard for the previous versions of YOLO to detect bounding boxes on image corners mainly due to the equations used to predict the bounding boxes, but the new equations presented above helped solving this problem by expanding the range of the center point offset from (0-1) to (-0.5,1.5) therefore the offset can be easily 1 or 0 (coordinates can be in the image's edge) as shown in the image in the left. Also the height and width scaling ratios were unbounded in the previous equations which may lead to training instabilities but now this problem has been reduced as shown in the figure on the right.
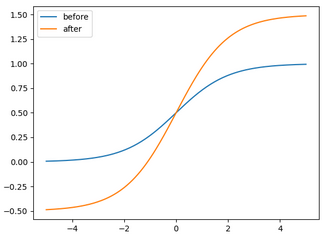
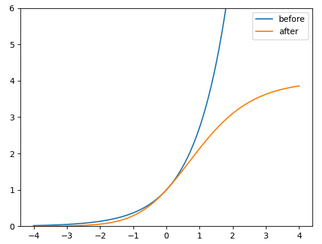
- The running environment: The previous versions of YOLO were implemented on the Darknet framework that is written in C, however YOLOv5 is implemented in Pytorch giving more flexibility to control the encoded operations.
6. YOLOv5 vs YOLOv4
As mentioned before, there is no research paper published for YOLOv5 from which we can drive the advantages and disadvantages of the model. However,some AI practitioners have tested the performance of YOLOv5 on many benchmarks, bellow is the summary of the benchmarks made by roboflow after a discussion with the author of the model.
- YOLOv5 is faster to train than YOLOv4
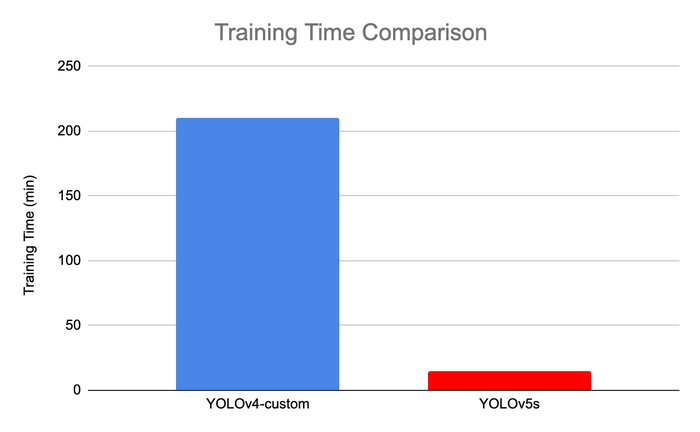
- YOLOv5 is lighter than YOLOv4
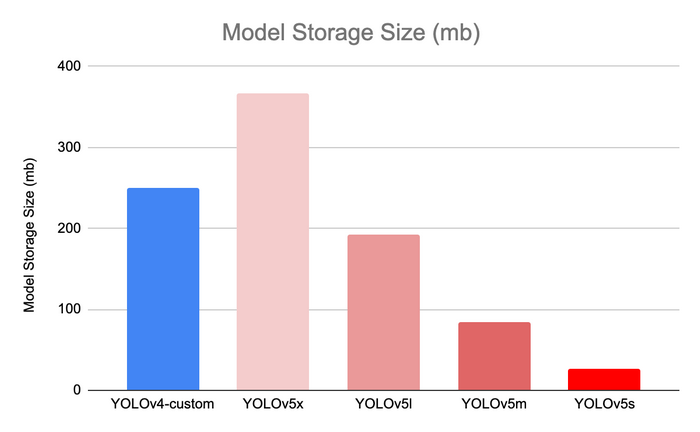
- YOLOv5 inference time is better than YOLOv4 inference time
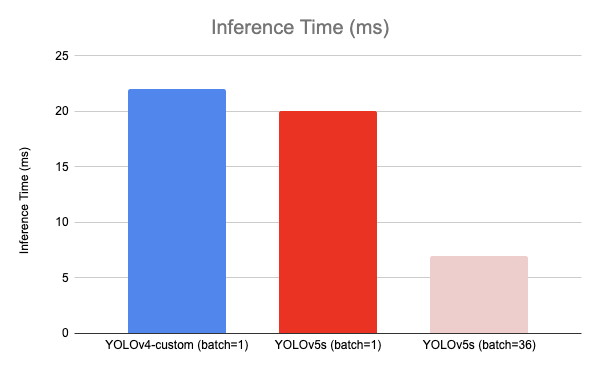
- YOLOv5 and YOLOv4 have the same mAP (mean Average Precision)
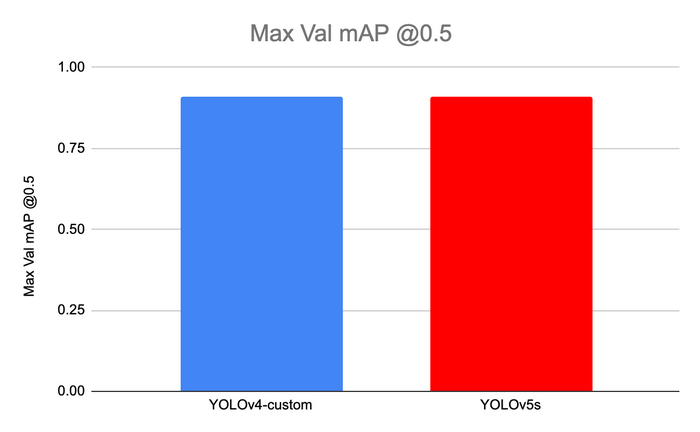
7. Conclusion
To wrap up what have been covered in this article, the key changes in YOLOv5 that didn't exist in previous version are: applying the CSPNet to the Darknet53 backbone, the integration of the Focus layer to the CSP-Darknet53 backbone, replacing the SPP block by the SPPF block in the model neck and applying the CSPNet strategy on the PANet model. YOLOv5 and YOLOv4 tackled the problem of grid sensitivity and can now detect easily bounding boxes having center points in the edges. Finally, YOLOv5 is lighter and faster than previous versions.
References
[1] BOCHKOVSKIY, Alexey, WANG, Chien-Yao, et LIAO, Hong-Yuan Mark. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934, 2020.
[2] XU, Renjie, LIN, Haifeng, LU, Kangjie, et al. A forest fire detection system based on ensemble learning. Forests, 2021, vol. 12, no 2, p. 217.
[3] WANG, Chien-Yao, LIAO, Hong-Yuan Mark, WU, Yueh-Hua, et al. CSPNet: A new backbone that can enhance learning capability of CNN. In : Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops. 2020. p. 390-391.
[4] HE, Kaiming, ZHANG, Xiangyu, REN, Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE transactions on pattern analysis and machine intelligence, 2015, vol. 37, no 9, p. 1904-1916.