
In this article, we will see what is BERT (bi-directional Encoder Representations from Transformers). How the BERT actually works and what are the embeddings in BERT that make it so special and functional compared to other NLP learning techniques.
Table of contents:
- Introduction to BERT
- Pretraining of BERT
- Embeddings in BERT
- Token Embeddings
- Segment Embeddings
- Position Embeddings
- Combining these embeddings
- Conclusion
Let us get started with Embeddings in BERT.
Introduction to BERT
BERT stands for Bi-directional Encoder Representations from Transformers. It was released in 2018 by a team at Google AI Language. As the name suggests the BERT model is made by stacking up multiple encoders of the transformer architecture on the top of another. The BERT architecture is designed to pretrain deep bidirectional representations from the unlabeled text by jointly conditioning on both left and right context in all layers.
As a result, the pre-trained BERT model can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications.
Pretraining of BERT
The goal of pretraining BERT is to make it understand what is language and what is context. And this is achieved by the use of Masked language Modelling and Next sentence Predictions.
Let's look at how these methods pretrain the model first to understand how the embeddings of BERT helps to make it more functional and fast.
Masked Language Modeling
In order to train the deep bi-directional representation, some part of the input token is masked at random and then those masked tokens are predicted. This is called masked language modeling. And at the final stage, the hidden vectors corresponding to the masked tokens are fed into the output softmax over the output vocabulary.
Key points
- BERT takes sentences with blanks (referred to as Masks) as input and the goal is to fill in the blanks i.e to output the mask tokens.
- This helps BERT to understand the bi-directional context within a language.
Next Sentence Prediction
To enable the model to perform Question Answering and Natural Language Interference, the BERT is pre-trained for binarized next sentence prediction task that can be trivially generated from any monolingual corpus. This helps the model to understand sentence relationships.
Key points
- Takes two sentences and checks if the second sentence follows the first.
- This helps BERT understand context across different sentences.
Thus using both MLM and NSP, BERT gets a good understanding of Language.
Embeddings in BERT
Embeddings are nothing but vectors that encapsulate the meaning of the word, similar words have closer numbers in their vectors.
The input embeddings in BERT are made of three separate embeddings. The diagram given below shows how the embeddings are brought together to make the final input token.
Note: Tokens are nothing but a word or a part of a word
But before we get into the embeddings in detail. Let's see why we need them.
The main reason for converting the words to embeddings is to make it easy for the model to work with. When the words are converted into embeddings, the model can understand the semantic importance of a word in the numeric form, and thus it can perform mathematical operations on it.
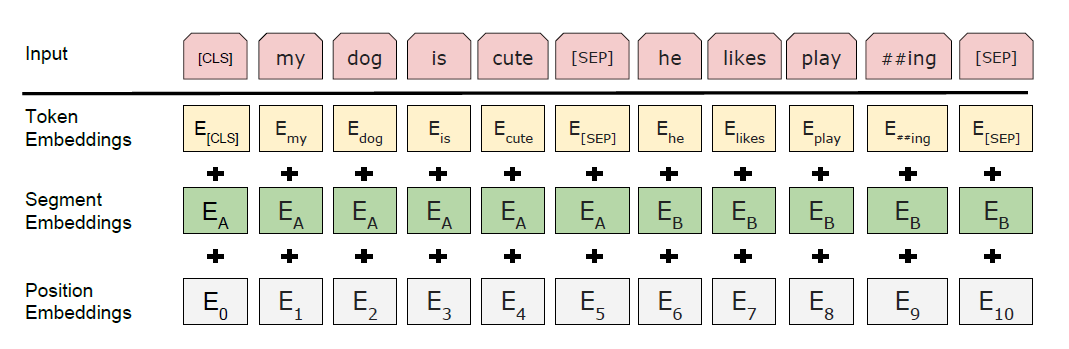
BERT input representation
At this point, it is good to know about some important tokens. In the above image, we can see apart from the word embeddings there are few other tokens like CLS and SEP. These are special tokens that convey specific meaning to the encoder let's look at them in more detail.
- CLS: It stands for classification. It is added to represent sentence-level classification. It is generally added at the start of a sequence so that it represents the entire sentence.
- SEP: The SEP is used during the next sentence prediction. It is a delimiter token that helps the model know which is the next sentence. In the case of a single sentence, it is just added at the end.
- MASK: This token is used during the MLM phase. It is used to represent the masked word to the model.
let's get into the various embeddings in detail.
Token Embeddings
Token embeddings are the pre-trained embeddings for different words
In order to create these pretrain token embeddings, a method called WordPiece tokenization is used to tokenize the text. This is a data-driven tokenization strategy that tries for a good balance of vocabulary size and out-of-vocab words.
WordPiece Tokens
WordPiece is a subword segmentation algorithm. It is initialized with individual characters and builds the vocabulary using the combination of those individual characters
Algorithm
- Initialize the basic elements with all the characters in the text
- Use the basic elements to build the language model
- New words are generated by combining two basic elements together and then adding it to the basic elements. While choosing the elements for the new word choose the one that when added to the mode increases the likelihood of the training data most.
- Go to step 2 until a predefined limit of word units is reached or the likelihood increase falls below a certain threshold.
Each word piece token will be converted into a 768-dimensional vector representation by the Token Embeddings layer.
Segment Embeddings
Segment embeddings are basically the sentence number that is encoded into a vector.
The model must know whether a particular token belongs to sentence A or sentence B in BERT. This is achieved by generating another, fixed token, called the segment embedding – a fixed token for sentence A and one for sentence B.
There are just two vector representations in the Segment Embeddings layer. All tokens belonging to input 1 are assigned to the first vector (index 0), whereas all tokens belonging to input 2 are assigned to the second vector (index 1).
Algorithm
- if the word belongs to the first sentence then 0
- if the word belongs to the second sentence then 1
For example, look at this sequence.
| [CLS] | I | Like | cats | [SEP] | I | Like | dogs |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
Position Embeddings
Position embeddings are the position of the word within that sentence that is encoded into a vector.
The token embeddings being a really important and useful embedding fails to give information about the position of the token in a sentence. So to solve it another embedding called the position embeddings is used.
The absolute position embedding is used to model how a token at one position attends to another token at a different position.
BERT was created to handle input sequences up to 512 characters long. The authors took advantage of the input sequences' sequential character by having BERT learn a vector representation for each point. This means that the Position Embeddings layer is a lookup table with a size of (512, 768) rows, with the first row representing the vector representation of any word in the first position, the second row representing any word in the second position, and so on.
Segment and Position embeddings are required for temporal ordering in BERT.
Combining these embeddings
The input embeddings are the sum of the token embeddings, the segmentation embeddings, and the position embeddings.
All the three embeddings mentioned above are summed element-wise to produce a single representation with shape (1, n, 768). This is the input representation that is passed to BERT’s Encoder layer.
Conclusion
The embeddings of the BERT are one of the main reasons for the incredible performance and speed of the model. With this article at OpenGenus, you must have a strong fundamental idea of embeddings in BERT.
If you want to know more about BERT, feel free to look into the original research paper here by Jacob Devlin, Ming-Wei Chang, Kenton Lee and Kristina Toutanova.