
Get this book -> Problems on Array: For Interviews and Competitive Programming
A new influential Intel paper argues the industry-standard roofline model hides most of what decides real GPU throughput - and offers a new way to see it, measure it and smooth it out. Here is why "performance ruggedness" could change how GPU kernels are tuned.

The hidden texture of GPU performance: Why "Peak FLOPs" isn't the whole story?
For two decades, the roffline model has been the go-to mental picture of accelerator performance: a chip has a peak compute rate and a peak memory bandwidth rate and any workload lives somewhere under that ceiling. It is elegant, it is useful and a new study argues, it quitely hides most of what actually determines real-world throughput.
What the Intel paper contributes - at a glance
- Performance ruggedness analysis - a new analytical framework that complements roofline by treating the entire multi-dimensional performance surface as the object of study, not a single peak number.
- The roughness metric - a simple, reusable measure of how "bumpy" performance is from one problem size to the next, making ruggedness quantifiable and comparable.
- A first-principles ideal landscape - a derived baseline (from core count, memory channels and tile geometry alone) that separates software fixable slowdowns from hardware bound ones.
- A dynamic programming based optimizer - routes any matrix shape to a nearby faster one with sero runtime cost, cutting performance roughness by 70% and raising average throughput by 30%.
- A reproducible, mechanism level diagnosis - a 32,768 configuration GPU sweep that rules out common myths and pins the residual bumpiness to specific silicon effects.
In "From Roofline to Ruggedness: Decomposing and Smoothing the GEMM Performance Landscape", Intel researcher Aditya Chatterjee shows that the performance of matrix multiplication - the single most important operation in modern AI - is far stranger than a smooth ceiling would suggest. Sweeping 32,768 problem sizes on an Intel Arc B580 GPU, the work finds that the:
two nearly identical matrix shapes, differing by a single step in one dimension, can run 30% apart in speed on the very same chip.
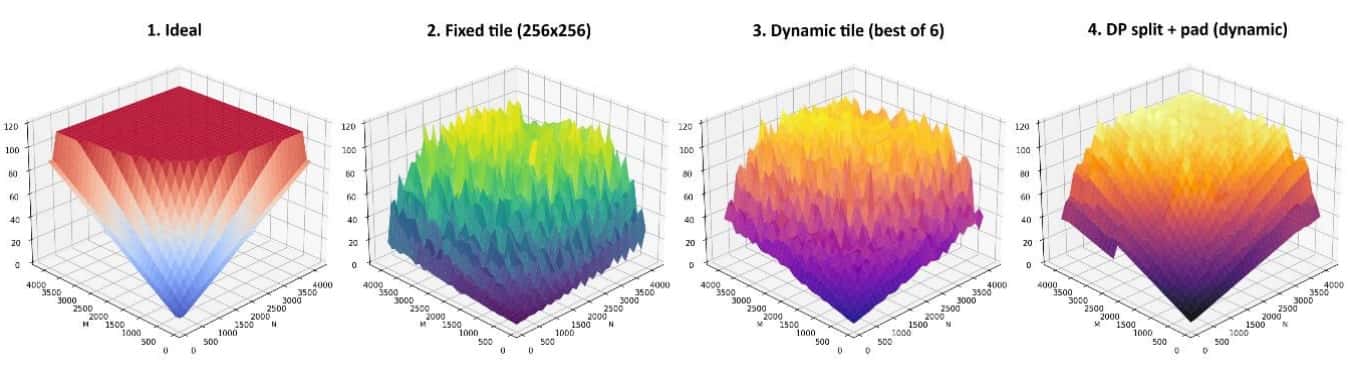
The performance surface isn't a clean curve; it is a rugged mountainous terrain.
A new lens: performance ruggedness
The paper's central idea is to stop summarizing a GPU with a single number and instead treat the entire performance surface as the object of study - a framework it calls performance ruggedness analysis where roofline says "you cannot go faster than this", ruggedness analysis says "here is exactly where, across the space of problem sizes, you fall short and why".
To make that concrete, the work introduces a simple, reusable roughness metric (how much throughput jumps from one problem size to the next) and a first principles ideal landscape to measure against. The gap between the two is then dissected, mechanism by mechanism, into the parts that software can fix and the parts that are baked into the silicon - the fixed number of compute cores, memory channels and the geometry of the matrix engine.
Turning rugged into smooth
Diagnosis is only half the story. The paper also delivers a fix: a novel dynamic-programming optimizer that, for any requested matrix size, instantly routes the computation to a nearly, better-behaved shape - padding or splitting the problem so it lands on a fast point of the terrain instead of a slow one. The payoff is striking: roughness drops by 70% and average throughput rises by 30%, with the routing decision precomputed so it costs essentially nothing at runtime.
Just as importantly, the study is careful about what it can't claim, Through a series of controlled experiments it rules out several popular explanations for the leftover bumpiness and traces them instead to concrete hardware quantization effects - right down to how a GPU's memory channels are addressed, the one ingredient that remains a vendor-internal secret.
Why it matters?
The implications reach well beyond one chip. AI compilers and autotuners spend enormous effort searching for fast kernel configurations; a map of where performance is ruggged tails them where that search actually pays off - and where a kernel is already as smooth as the hardware allows. For teams that must hit latency targets, ruggedness analysis turns "it's usually fast" into a quantitative, per-shape guarantee,
The paper also sketches how others can build on it: mapping the same ruggedness terrain across GPU vendors to compare their silicon "fingerprints", extending it across operation types beyond matrix multiply, and closing the last gaps with vendor-specific scheduling. The framework is deliberately portable - it depends only on a device's core count, channel count and tile geometry.
The takeaway
Roofline told us the ceiling. The work maps the floor we actually walk on - and shopws that, with the right analysis and a clever optimizer, a lot of that rough ground can be smoothed out. As AI workloads push hardware ever harder, knowing not just the peak but the texture of performance may prove to be the more practical kind of map.
The paper is available on ArXiv: Link
How to cite this Intel paper?
@article{chatterjee2026roofline,
title={From Roofline to Ruggedness: Decomposing and Smoothing the GEMM Performance Landscape},
author={Chatterjee, Aditya},
journal={arXiv preprint arXiv:2605.29752},
year={2026}
}
Reference
[1] Chatterjee, Aditya. "From Roofline to Ruggedness: Decomposing and Smoothing the GEMM Performance Landscape." arXiv preprint arXiv:2605.29752 (2026).