
In this article, we have explored Text Preprocessing in Python using spaCy library in detail. This is the fundamental step to prepare data for specific applications.
Some of the text preprocessing techniques we have covered are:
- Tokenization
- Lemmatization
- Removing Punctuations and Stopwords
- Part of Speech Tagging
- Entity Recognition
Analyzing, interpreting and building models out of unstructured textual data is a significant part of a Data Scientist's job. Many deep learning applications like Natural Language Processing (NLP) revolve around the manipulation of textual data. For Example -
You are a business firm which has launched a new website or a mobile application-based service. Now, you have the data containing the customer reviews for your product, and you wish to do a Consumer Sentiment analysis on these reviews using machine-learning algorithms.
However, to make this data structured and computationally viable for algorithms, we need to preprocess it.
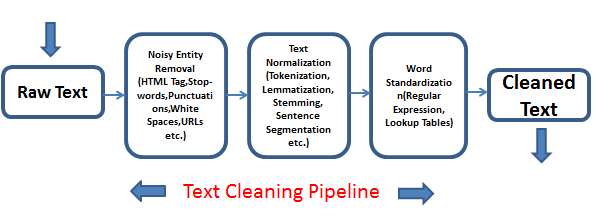
So, here we are going to learn about various fundamental preprocessing techniques for our textual data. We are going to work with spaCy library in Python, which is among the numerous libraries (like nltk,gensim,etc.) used for textual transformations.
Here are the topics which we are going to cover:
- Tokenization
- Lemmatization
- Removing Punctuations and Stopwords
- Part of Speech Tagging
- Entity Recognition
Tokenization
Tokenization is the process of chopping down the text into pieces, called tokens, while ignoring characters like punctuation marks ("," , "." , "!" ,etc.) and spaces. spaCy's functions allows us to tokenize our text via two ways -
- Word Tokenization
- Sentence Tokenization
Below is a sample code for word tokenizing our text.
Below is a sample code for word tokenizing our text
#importing libraries
import spacy
#instantiating English module
nlp = spacy.load('en)
#sample
x = "Embracing and analyzing self failures (of however multitude) is a virtue of nobelmen."
#creating doc object containing our token features
doc = nlp(x)
#Creating and updating our list of tokens using list comprehension
tokens = [token.text for token in doc]
print(tokens)
Result
['Embracing', 'and', 'analysing', 'self', 'failures', '(', 'of', 'however', 'multitude', ')', 'is', 'a', 'virtue', 'of', 'nobelmen', '.']
Notice how we get a list of tokens containing words and punctuations. Here, the algorithm identifies contractions like are 'nt as two distinct words; "are" and "'nt".
We can obtain sentence tokenization (splitting text into sentences) as well if we wish to. However, we would have to include a preprocessing pipeline in our "nlp" module for it to be able to distinguish between words and sentences.
Below is a sample code for sentence tokenizing our text.
nlp = spacy.load('en')
#Creating the pipeline 'sentencizer' component
sbd = nlp.create_pipe('sentencizer')
# Adding the component to the pipeline
nlp.add_pipe(sbd)
x = "Embracing and analyzing self failures (of however multitude) is a virtue of nobelmen. And nobility is a treasure few possess."
#creating doc object carring our sentence tokens
doc = nlp(text)
#Creating and updating our list of tokens using list comprehension
tokens = [token for token in doc.sents]
print(tokens)
Result
[Embracing and analyzing self failures (of however multitude) is a virtue of nobelmen., And nobility is a treasure few possess.]
Tokenization is a fundamental step in preprocessing, which helps in distinguishing the word or sentence boundaries and transforms our text for further preprocessing techniques like Lemmatization,etc.
Lemmatization
Lemmatization is an essential step in text preprocessing for NLP. It deals with the structural or morphological analysis of words and break-down of words into their base forms or "lemmas".
For Example - The words walk,walking,walks,walked are indicative towards a common activity i.e. walk. And since they have different spelling structure, it makes it a confusing task for our algorithms to treat them differently. So, these will be treated under a single lemma.

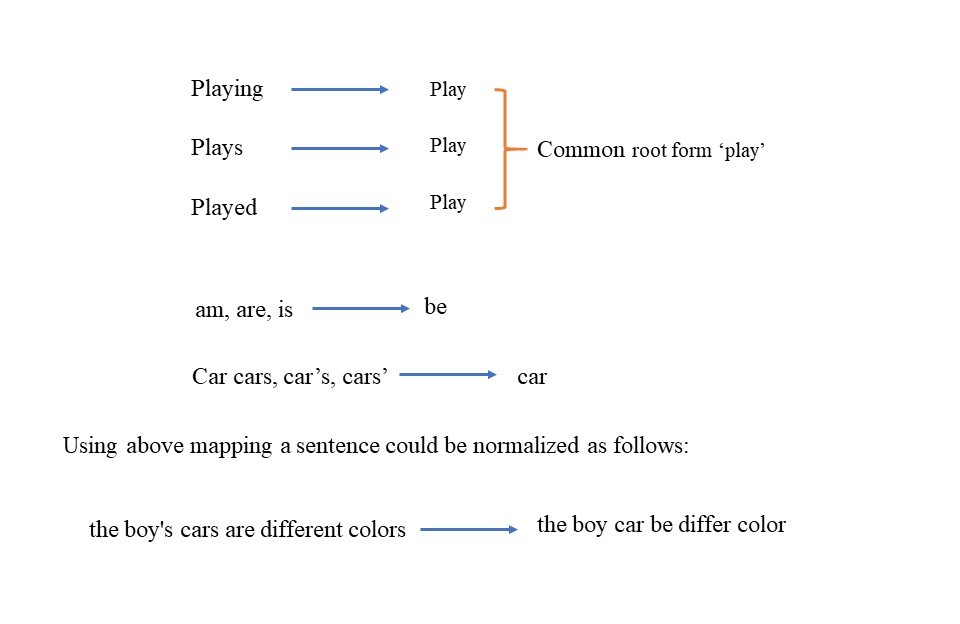
We can use spaCy's built-in methods for lemmatizing our text.
#importing libraries
import spacy
#instantiating English module
nlp = spacy.load('en')
#sample
x = "Running down the street with my best buddy."
#creating doc object containing our token features
doc = nlp(x)
#Creating and updating our list of tokens using list comprehension
tokens = [[token.text,token.lemma_] for token in doc]
print(tokens)
Result
[['Running', 'run'], ['down', 'down'], ['the', 'the'], ['street', 'street'],
['with', 'with'], ['my', '-PRON-'], ['best', 'good'], ['buddy', 'buddy']]
As you can clearly see, the words such as running are broken down to their lemmas i.e. - run. Lemmatization greatly enhances our text for better and faster optimization.
Removing Stop Words
While working with textual data, we encounter many data instances which aren't of much use for our analysis as they do not add any meaning/relevance to our data. These can be pronouns (like I, you, etc.) or words like are , is , was , etc.
These words are called Stop words. We can use the built in STOP_WORDS from spaCy for filtering our text.
spaCy's built in stop words list can be viewed as following -
spaCy's built in stop words list can be viewed as following
from spacy.lang.en.stop_words import STOP_WORDS
stop = STOP_WORDS
print(stop)
Result
{'another', 'go', 'please', 'him', 'move', 'also', 'and', 'beside', 'hers', 'my', 'noone', 'off', 'onto', 'rather', 'itself', 'keep', 'say', '‘m', '’m', 'whatever', '‘ve', 'hence', 'otherwise', 'neither', 'up', 'only', 'any', '’re', 'down', 'whereupon', 'name', 'thereupon', 'are', 'among', "'ve", 'twenty', 'to', 'side', 'can', 'whereas', 'thereby', 'enough', 'ca', 'few', 'fifteen', 'anyway', 'full', 'nobody', 'serious', 'between', 'without', 'than', 'besides', 'whenever', 'whoever', 'her', 'of', 'amount', 'herein', 'hundred', 'although', 'around', 'was', 'at', 'could', 'fifty', 'n‘t', 'beforehand', 'everywhere', 'before', 'into', 'been', 'much', 'his', 'never', 'nothing', 'that', 'two', 'no', 'from', 'hereupon', 'each', 'himself', 'being', 'everything', 'mostly', 'put', 'thence', 'third', 'via', '’s', 're', 'be', 'top', 'both', 'indeed', 'might', 'else', 'through', 'elsewhere', 'whereafter', 'whose', 'six', 'sixty', 'then', 'as', 'above', 'n’t', 'anywhere', 'hereafter', 'five', 'every', 'twelve', 'why', 'unless', 'us', "'re", 'often', 'whither', 'do', 'when', 'beyond', 'themselves', 'about', 'whether', '‘ll', 'except', 'who', 'under', 'myself', 'using', 'were', 'by', 'for', 'therein', 'seem', 'due', 'he', 'perhaps', 'these', 'again', 'own', 'three', 'has', 'together', '‘re', 'or', "'s", 'how', 'more', 'we', 'becomes', 'this', 'there', 'already', 'will', 'because', 'whence', 'cannot', 'ever', 'their', 'per', 'almost', 'where', 'afterwards', 'bottom', 'front', 'others', 'over', 'seemed', 'those', 'somewhere', 'not', 'take', 'while', 'well', 'but', 'after', 'below', 'part', 'one', 'many', 'out', 'yourself', 'other', 'anyhow', "'d", 'amongst', 'some', 'such', 'yet', 'same', 'sometimes', 'seeming', 'forty', 'ours', 'give', 'former', 'across', 'yours', 'a', 'several', 'make', 'the', 'call', 'though', 'whole', 'yourselves', 'anything', 'first', 'ourselves', 'must', 'our', 'since', '‘d', 'formerly', 'nowhere', "n't", 'very', 'get', 'became', 'they', 'anyone', 'she', 'does', 'me', 'an', 'whereby', 'wherein', 'all', 'becoming', 'had', 'may', 'so', 'which', 'if', "'m", 'on', "'ll", 'herself', 'nine', 'am', 'regarding', 'namely', '‘s', 'done', 'your', '’ve', 'empty', 'you', 'either', 'now', 'throughout', 'toward', 'moreover', '’ll', 'four', 'meanwhile', 'ten', 'have', 'everyone', 'mine', 'nevertheless', 'within', 'with', 'most', 'latter', 'various', 'would', 'last', 'thru', 'thereafter', 'once', 'should', 'doing', 'upon', 'quite', 'back', 'i', 'towards', 'less', 'is', 'just', 'eleven', 'always', 'nor', 'wherever', 'further', 'whom', 'therefore', 'however', 'along', 'during', 'none', '’d', 'least', 'someone', 'used', 'what', 'here', 'eight', 'hereby', 'it', 'made', 'behind', 'alone', 'its', 'see', 'somehow', 'even', 'sometime', 'still', 'thus', 'in', 'latterly', 'next', 'did', 'something', 'until', 'really', 'show', 'them', 'too', 'become', 'seems', 'against'}
Now we can use the "is_stop" attribute of the token object for filtering out the stop words from our sample text.
#importing libraries
import spacy
#instantiating English module
nlp = spacy.load('en')
#sample
x = "Running down the street with my best buddy."
#creation of doc object containing our token features
doc = nlp(x)
#Creating and updating our list of tokens using list comprehension
tokens = [token.text for token in doc]
print(tokens)
#Creating and updating our list of filtered tokens using list comprehension
filtered = [token.text for token in doc if token.is_stop == False]
print(filtered)
Result
['Running', 'down', 'the', 'street', 'with', 'my', 'best', 'buddy']
['Running', 'street', 'best', 'buddy']
You can compare the above two lists and notice words such as down,the,with and my have been removed.Now, similarly, we can also remove punctuation from our text as well using "isalpha" method of string objects and using list comprehensions.
#sample
x = "BLIMEY!! Such an exhausting day, I can't even describe."
#creation of doc object containing our token features
doc = nlp(x)
#Unfiltered tokens
tokens = [token.text for token in doc]
print(tokens)
#Filtering our tokens
filtered = [token.text for token in doc if token.is_stop == False and
token.text.isalpha() == True]
print(filtered)
Result
['BLIMEY', '!', '!', 'Such', 'an', 'exhausting', 'day', ',', 'I', 'ca', "n't", 'even', 'describe', '.']
['BLIMEY', 'exhausting', 'day', 'describe']
You can observe the differences between the two lists. Indeed, spaCy makes our work pretty easy.
Part-of-Speech Tagging (POS)
A word's part of speech defines the functionality of that word in the document. For example - in the text Robin is an astute programmer, "Robin" is a Proper Noun while "astute" is an Adjective.
We will use the en_core_web_sm module of spacy for POS tagging.
#importing libraries
import spacy
#instantiating English module
nlp = spacy.load('en_core_web_sm')
#sample
x = "Robin is an astute programmer"
#Creating doc object
doc = nlp(x)
#Extracting POS
pos = [[token.text,token.pos_] for token in doc]
print (pos)
Result
[['Robin', 'PROPN'], ['is', 'AUX'], ['an', 'DET'], ['astute', 'ADJ'],
['programmer', 'NOUN']]
Question 1
Which Python library is not used for Text Preprocessing ?
Entity Recognition
Entity recognition is a text preprocessing technique that identifies word-describing elements like places, people, organizations, and languages within our input text.
We will make use of ".ents" attribute of our doc object.
#sample article
x = u""" India is considering a proposal to guarantee as much as 3
trillion rupees ($39 billion) of loans to small businesses as part of a plan to
restart Asia's third-largest economy, which is reeling under the impact of a 40-
day lockdown, people with knowledge of the matter said."""
#creating doc object
bloomberg= nlp(x)
#extracting entities
entities=[(i, i.label_, i.label) for i in bloomberg.ents]
print(entities)
Result
[(India, 'GPE', 384), (as much as 3 trillion rupees, 'QUANTITY', 395), ($39 billion, 'MONEY', 394), (Asia, 'LOC', 385), (third, 'ORDINAL', 396)]
Here, India has been recognized as GPE(Geopolitical Entity) while $39 billion has been given MONEY entity, which is indeed true. We can visualize our entities in a prettier way by using displacy from the spaCy module.
from spacy import displacy
displacy.render(bloomberg, style = "ent",jupyter = True)
Result

And while there are many other processing techniques, we have covered the most fundamental ones. These techniques go on a long way in helping us extract useful insights from our unstructured textual data.
Meanwhile, enjoy these questions :)
Question 2
Which operation is used to reduce the words to their cannonical/dictionary/base form ?
Question 3
Which of the following is a stop word ?
A note on Bag-of-Words model
We have previously discussed the necessity for manipulation and transformation of our textual data to make it suitable for various ML algorithms. And we have discussed many preprocessing techniques that help us improve the quality of our input data. However, one crucial fact to keep in mind is that algorithms perform their respective tasks on numerical data rather than textual data. Hence,it would require us to convert our preprocessed data into a machine-friendly numerical format.
A Bag of Words model essentially extracts features from textual data in a form acceptable for machine processing. This model simply creates a vocabulary of words from our document or list of documents and then creates an array of numbers for all each document, mapping the document words with either the count or frequency of words from vocabulary.
Sounds confusing, right? Let's see.
Consider this quote from Opera Winfrey, "If you look at what you have in life, you'll always have more. If you look at what you don't have in life, you'll never have enough.". Now, let us use a bag of words model on it. For ease of understanding, we are going to ignore the preprocessing steps (like Stopwords removal,etc.).
Now using BOW, we obtain a list of words or features -
['always', 'at', 'don', 'enough', 'have', 'if', 'in', 'life', 'll', 'look', 'more', 'never', 'what', 'you']
This alphabetically arranged list of words will now be used for transformation. After transforming the first line of the quote ("If you look at what you have in life, you'll always have more.") based on the number of times that word appearing in that line, we get the following list -
'always' = 1
'at' = 1
'don' = 0
'enough' = 0
'have' = 2
'if' = 1
'in' = 1
'life' = 1
'll' = 1
'look' = 1
'more' = 1
'never' = 0
'what' = 1
'you' = 3
The above list can be represented as an array and passed on to our algorithms as training data. Note, that the above interpretation uses word count for vectorization. There can be other different ways to vectorize as well, such as using word frequency or Term Frequency-Inverse Document Frequency(TF-IDF). You can use sklearn's CountVectorizer or TfidfVectorizer as per your requirements.
With this article at OpenGenus, you must have the complete idea of preprocessing in Python using spaCy library. Enjoy.