
Open-Source Internship opportunity by OpenGenus for programmers. Apply now.
In this article, we have presented the most important Interview Questions on Random Forest.
1. What is the Random Forest Algorithm?
A random forest algorithm is an ensemble learning technique, which means it combines numerous classifiers to enhance a model's performance. In order to determine the output depending on the input data, a random forest uses several decision tree (Classification and Regression Tree) models. It uses bagging to generate the decision trees it uses by using samples and randomly chosen features (variables).
Now, the modal (most frequent occuring) output among all the decision trees is picked as the one to move forward with when a random forest is used to forecast the outcome of a classification task. But if the goal is to forecast a regression problem's outcome, the mean (average) of all the decision trees' outputs is obtained before moving on.
2. For what applications are random forests used?
Numerous sectors have used the random forest algorithm to help them make better business decisions. Examples of use cases are:
- Finance: This method is favoured over others since it takes less time to manage and pre-process data. It can be used to assess high-risk consumers for fraud and issues with option pricing.
- Healthcare: The random forest approach is used in computational biology to solve issues including classifying gene expression, finding biomarkers, and annotating sequences (link resides outside IBM; PDF, 737 KB). Doctors can therefore estimate pharmacological reactions to certain drugs.
- E-commerce: Cross-selling can be accomplished by using recommendation engines.
3. How does a Random Forest Work?
There are three key hyperparameters for random forest algorithms that must be set prior to training. Node size, tree count, and sampled feature count are a few of them. From there, classification or regression issues can be resolved using the random forest classifier. Each decision tree in the ensemble that makes up the random forest method is built of a data sample taken from a training set with replacement known as the bootstrap sample.
One-third of the training sample—also referred to as the out-of-bag (oob) sample—is set aside as test data; we'll return to this sample later. The dataset is subsequently given a second randomization injection by feature bagging, increasing dataset diversity and decreasing decision tree correlation.
The prediction will be determined differently depending on the type of issue.
The individual decision trees will be averaged for the regression job, and for the classification task, the predicted class will be determined by a majority vote, or the most common categorical variable.
The prediction is then finalized by cross-validation using the oob sample.
4. Why do we need the random forest algorithm?
It's a great question, and the response is simple. A random forest uses cross-validation to provide results that are more accurate and can be utilized for either classification or regression problems. Even missing values are handled, and a larger data collection with many features can be handled (dimensions). Most crucially, because it selects random features and generalizes well across the available data, it accomplishes all of this with minimal over-fitting. This makes it a lot more accurate algorithm than the traditional decision tree method, which is deficient in the majority of the aforementioned characteristics.
5. What are the advantages of the random forest methodology?
The random forest approach has a variety of significant benefits when applied to classification or regression tasks.
Some of them consist of:
Less chance of overfitting: Decision trees have a propensity to closely fit all the samples contained in training data, which increases the possibility of overfitting.
The classifier won't, however, overfit the model when there are a large number of decision trees in a random forest since the averaging of uncorrelated trees reduces the total variance and prediction error.
Flexibility: Random forest is a well-liked approach among data scientists since it can accurately handle both classification and regression jobs.
The random forest classifier benefits from feature bagging by maintaining accuracy even when some of the data is missing, which makes it a useful tool for guessing missing values.
Simple evaluation of feature contribution: Random forest makes it simple to evaluate variable contribution. There are various methods for determining feature relevance.
To gauge how much the model's accuracy declines when a particular variable is removed, the gini importance and mean drop in impurity (MDI) are frequently utilized. A different importance metric is permutation importance, often known as mean decrease accuracy (MDA). By randomly permuting the feature values in oob samples, MDA can determine the average reduction in accuracy.
6. What are the disadvantages of the random forest methodology?
The random forest approach has a variety of significant drawbacks when applied to classification or regression tasks.
Process that takes a long time: Because random forest methods can handle big data sets, they can make predictions that are more accurate. However, because they must compute data for each individual decision tree, they can take a long time to process data.
More resources are needed: Because random forests analyze bigger data sets, more resources are needed to store that data.
More complex: When compared to a forest of decision trees, a single one's prediction is simpler to understand.
7. How do random forests maintain accuracy when data is missing?
They often employ two techniques to accomplish this:
- Since the available data is not being used, dropping or eliminating the data points with no values is not a desirable option.
- Using the median to complete the missing values if they are numerical or the mode to complete the missing values if they are categorical. Even Nevertheless, there are limitations since occasionally there is insufficient data to paint an accurate picture.
8. What are ensemble methods?
Multiple models (commonly referred to as "weak learners") are taught to tackle the same problem using the ensemble learning paradigm, which then combines the findings to produce better ones. The basic claim is that by properly combining weak models, we can produce more precise and/or reliable models.
9. How do you improve random forest accuracy?
Depending on your aim and data. One of the numerous things you must take into account is the hyperparameter. You hardly ever obtain good accuracy if the parameter you are using is incorrect or irrelevant.
It may be feasible to identify a decent mix of parameters by manually adjusting them repeatedly, but I advise using methods like GridSearch or Bayesian optimization to do so.
10. Why is Random Forest Algorithm popular?
One of the most well-liked and frequently applied machine learning techniques for classification issues is Random Forest. Although it also works well with regression problem statements, the classification model is where it shines the most.
Modern data scientists now use it as a deadly weapon to improve the forecasting model. The algorithm's best feature is that it relies on a minimal number of assumptions, making data preparation simpler and faster.
11. Why Random Forest is not affected by outliers?
Tree methods, on the other hand, are "contributory" methods in which only local points, or those in the same leaf node, influence an estimate for a particular point. Outliers in the output have a "quarantined" effect. As a result, outliers that might drastically alter the precision of some algorithms have less of an impact on a Random Forest's forecast.
12. What are assumptions of random forest?
Some decision trees may forecast the correct output while others may not since the random forest combines numerous trees to predict the dataset class. But when all the trees are combined, they forecast the right result. Consequently, the following two presumptions for an improved Random forest classifier:
- For the dataset's feature variable to predict true outcomes rather than a speculated result, there should be some actual values in the dataset.
- Each tree's predictions must have extremely low correlations.
13. Difference Between Random Forest And Decision Tree
Here are some of the most significant distinctions between Random Forest and Decision Tree:
- Data processing: The decision trees use an algorithm to decide on nodes and sub-nodes; a node can be split into two or more sub-nodes, and by creating sub-nodes it gives another homogeneous sub-node, so we can say that the nodes have been split. The random forest is the combination of multiple decision trees, which is the class of dataset. Some decision trees out of it may give the correct output and others may not give it correctly, but all trees together predict
The split is carried out using the best data that can be used initially, and the operation has been repeated until all of the child nodes have reliable data. - Complexity: The decision tree, which is used for both classification and regression, is a straightforward series of choices that are taken to obtain the desired outcomes. The advantage of the simple decision tree is that this model is simple to interpret, and when building decision trees, we are aware of which variable and what is the value of the variable is using to split the data, and as a result, the output will be predicted quickly. In contrast, the random forest is more complex because it combines decision trees, and when building a random forest, we have to define the number of trees we want to build and how many variables we need.
- Accuracy: Compared to decision trees, random forest forecasts outcomes with more accuracy. We can also say that random forests build up many decision trees and that combines together to give a stable and accurate result. When we are using an algorithm to solve the regression problem in a random forest, there is a formula to get an accurate result for each node, whereas the accuracy of results is increased by using a combination of learning models.
- Overfitting: When using algorithms, there is a risk of overfitting, which can be viewed as a general bottleneck in machine learning. Overfitting is the important issue in machine learning.
When machine learning models are unable to perform well on unknown datasets, this is a sign of overfitting. This is especially true if the error is found on the testing or validation datasets and is significantly larger than the error on the training dataset. Overfitting occurs when models learn fluctuation data in the training data, which has a negative impact on the performance on the new data model.
Due to the employment of several decision trees in the random forest, the danger of overfitting is lower than that of the decision tree.
The accuracy increases when we employ a decision tree model on a given dataset since it contains more splits, which makes it easier to overfit the data and validate it.
14. How feature importance is calculated in random forest?
There are two techniques to calculate the feature importance integrated into the Random Forest algorithm:
The mean decrease impurity, also known as Gini significance, is calculated from the Random Forest structure.
Let's examine the Random Forest's architecture.
It consists of many Decision Trees.
There are internal nodes and leaves in every decision tree.
The internal node uses the chosen characteristic to decide how to split the data set into two distinct sets with related responses.
The criteria used to choose the features for internal nodes might range from gini impurity or information gain for classification tasks to variance reduction for regression activities. We can gauge how each feature reduces the split's impurity (the feature with highest decrease is selected for internal node).
We can track the average reduction in impurity for each feature.
The average of all the trees in the forest serves as a proxy for the significance of a feature.
This technique is offered in the Scikit-Learn Random Forest implementation (for both classifier and regressor).
The relative values of the computed importances should be considered when using this method, it is important to note.
The major benefit of this approach is computation speed; all necessary values are computed while the trainees are in Radom Forest. The method's shortcomings include its propensity to favor (select as significant) numerical features and categorical features with high cardinality. Additionally, when associated features are present, it may choose one trait while ignoring the significance of the other (which can lead to wrong conclusions).
Based on the mean drop in accuracy, the Mean Decrease Accuracy approach computes the feature importance on permuted out-of-bag (OOB) data. The scikit-learn package does not include this method's implementation.
15. Does Random Forest need Pruning? Why or why not?
Very deep or fully-depth decision trees have a tendency to pick up on the data noise. They overfit the data, resulting in large variation but low bias. Pruning is an appropriate method for reducing overfitting in decision trees.
However, in general, full-depth random forests would do well. The correlation between the trees (or weak learners) would be poor since random forests training uses bootstrap aggregation (or sampling with replacement) together with random selection of features for a split. Because the trees are not coupled, even though each individual tree would have a high variance, the ensemble output would be suitable (lower variance and reduced bias).
16. Explain how the Random Forests give output for Classification, and Regression problems?
Classification: The Random Forest's output is the one that the majority of trees have chosen.
Regression: The mean or average forecast of each individual tree is the Random Forest's output.
17. How is it possible to perform Unsupervised Learning with Random Forest?
The goal of a decision tree model is to arrive at one of the predetermined output values by starting with some input data and proceeding through a sequence of if-then stages.
In contrast, a random forest model combines a number of decision trees that have been trained using different subsets of the starting data.
For instance, you might gather information on how frequently consumers have visited the bank in the past and what services they have used if you wanted to utilize a single decision tree to predict how frequently specific customers would use a specific service offered by the bank. You would identify particular qualities that affect the customer's decision. The decision tree would produce rules that would enable you to forecast whether a consumer will use the services or not.
If you input the same data into a random forest, the algorithm will produce multiple trees from a set of customers that are chosen at random. The sum of the individual outcomes of each of those trees would be the forest's output.
18. How would you improve the performance of Random Forest?
Attempting the following measures may help Random Forest function better:
- Utilizing feature engineering and a dataset of greater quality. It is not desirable for the model to use too many features and data, hence it is occasionally necessary to perform some feature reduction.
- Adjusting the algorithm's hyperparameters.
- Trying several algorithms
19.What are proximities in Random Forests?
The word "proximity" refers to the similarity or closeness of two cases.
For each pair of cases, observations, or sample points, proximity is determined. Two cases are closer together if they share the same terminal node in a single tree. The proximities are normalized by dividing by the total number of trees at the conclusion of the run of all trees. In order to replace missing data, find outliers, and create enlightening low-dimensional perspectives of the data, proximity is used.
20. What does Random refer to in Random Forest?
In the process of choosing the features for each tree, randomness is introduced.
For each tree formed, the algorithm chooses a random set of features to split a node from rather than looking for the most crucial trait.
As a result, the model can be more flexible, factor chaos, and have a less deterministic structure, which improves out-of-sample performance while lowering the danger of overfitting.
21. What is Out-of-Bag Error?
OOB (out-of-bag) error
A method of calculating the prediction error that enables the Random Forest to be fitted and validated while being trained is known as out-of-bag (OOB) error/out-of-bag estimate.
Let's use the following illustration to better comprehend that:
Assume that each of the 20 students is given a different subset of the data (i.e. as seen in Stages 1, and 2). An observation may be contained within the subsets of more than one learner because we are sampling with replacement. Therefore, we'll calculate the Out-of-bag in the following way:
- Repeat after each observation
- Determine the students who did not previously have this observation in their subset for each observation.
- Use the students you specified above to carry out the prediction for this observation.
- The prediction error for each observation is averaged
This allows us to assess the predictions made based on the observations that weren't used to train the basic learners. This also eliminates the requirement for any validation set.
22. What is Entropy?
Entropy, often known as Shannon Entropy, is a measure of how random or uncertain the data is for a finite collection S. It is denoted by H(S).
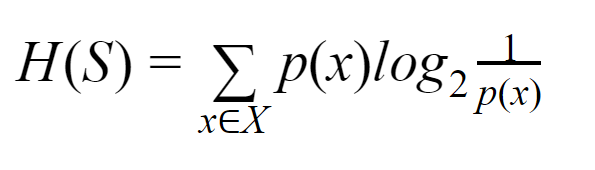
Simply put, it gauges purity to foretell a specific event. The root node serves as the foundation for the top-down construction of the decision tree. This root node's data is further divided or categorized into subsets with homogeneous instances.
23. Why Random Forest models are considered not interpretable?
Decision trees can readily be transformed into rules that improve the results' human interpretability and provide an explanation for the choices taken.
The usual guideline is to employ as many trees as you can for Random Forest. Most of the time, it would be difficult to comprehend why a group of hundreds of trees decided as they did.
24. Why is the training efficiency of Random Forest better than Bagging?
For Random Forest, just a subset of all features are randomly chosen, and the best split feature from the subset is used to divide each node in a tree. This is how Random Forest differs from Bagging. All features are taken into account when separating a node while bagging.
Because bagging takes into account all of the attributes, random forest has a superior training efficiency.
25. Explain how it is possible to get feature importance in Random Forest using Out Of Bag Error
The Out of Bag Error is used in the following technique to determine feature importance:
Without making any changes, generate the out of bag error for the base tree.
The standard out of bag error is this. Determine the range of values that each characteristic in the data used to construct the tree can be. Specifically, what are the data's maximum and minimum values? Randomly permute the values of each feature in all the data points between its maximum and minimum for each feature, one at a time. Find the out of bag mistake next after only permuting one feature.
The difference between the current out-of-bag error and the previous out-of-bag error should be calculated. It is almost certain that the new out of bag error will be higher than the mean value. Restart the procedure by changing a new feature after restoring the permuted features to their original values. The most crucial features are those whose inaccuracy increases the most when they are permuted. The least significant features are those with the smallest increase in inaccuracy.
This approach can be compared to withholding individual machine pieces from someone but allowing them to assemble the entire machine. The part must be crucial if the assembly fails catastrophically. The parts must not be very crucial if you can't tell the difference after the machine has been created.
26.Give some reasons to choose Random Forests over Neural Networks
In terms of processing cost, Random Forest is less expensive than neural networks. A GPU might be required to finish training neural networks.
In comparison to random forest, neural networks require a lot more information.
Neural networks operate like a "black box," where the creator is unable to see how the output is determined. A vast number of trees in Random Forest might make it challenging to understand the ensemble even though each tree is distinct and easily understood. The most representative trees in an ensemble can be found in a number of different methods. The Random Forest is therefore superior in this sense.
When given unusual inputs, neural networks frequently have a higher risk of deviating from the expected behavior.
27. How can you tell the importance of features using Random Forest?
The ability to determine the relative value of various features in the data is one of the most intriguing things that can be done using Random Forest.
To see how different features affect the result, the various features and the output can be displayed and evaluated for outliers.
Using the information gain at each stage of the tree to calculate the relative information gain between various features is one way to gauge the significance of a feature.
The algorithm's steps are provided in the list below:
- Start with an array that is zero-filled and the same size as the number of features in the model.
- Using the information that was used to create the tree, traverse it.
When you reach a branch in the tree, identify the feature that branch relied on. - Every branch divides on a single, unique trait. Instead of going down a separate branch of the tree, count the number of data points that reach each one.
- Instead of before the branch, the knowledge gain is calculated after the fork.
This is true regardless of how information gain is measured (e.g. Gini, Entropy). - The information gain is multiplied by the quantity of data points that reach the branch and is added to the array at the feature where the data points are being separated.
- The array is normalized after the information gain for each branch has been added.
- The calculation of the feature importance for each tree in the Random Forest is then repeated for each tree in turn. The feature importance of the entire Random Forest is then calculated by averaging it.
28. How to use Isolation Forest for Anomalies detection?
Similar to Random Forests, Isolation Forests (IF) are constructed using decision trees. Additionally, this model is unsupervised because there are no predefined labels present. The foundation of IsolationForests is the idea that anomalies are the "few and different" data items. Randomly subsampled data is processed in an isolation forest using a tree structure based on randomly chosen attributes. Since it took more cuts to isolate the samples that traveled further into the tree, they are less likely to be abnormalities.
The following steps are involved in creating or training an isolation tree given a dataset:
- Pick a random subset of the information
- Prior to isolating each point in the dataset:
- Choosing a feature one at a time
- Divide the feature at a chance location within its range.
- An outlier point can be separated in a small number of divisions, as seen in the image below, whereas an interior point necessitates more partitions.
Given a fresh point, the process of prediction entails: - Perform a binary search across each itree in the forest, traveling until you find a leaf.
- Using the depth of the path to the leaf as the basis, calculate the anomaly score.
- Create an overall anomaly score for the point by adding the anomaly scores from each of the separate itrees.
In general, interior points will have a substantially longer trip to the leaf than anamolous points, making them more difficult to isolate.
29. What do you mean by Bagging?
The ensemble learning technique known as bagging, often referred to as bootstrap aggregation, is frequently used to lessen variance within a noisy dataset. In bagging, a training set's data is randomly sampled and replaced, allowing for multiple selections of the same data points. Following the generation of several data samples, these weak models are independently trained, and depending on the task—for example, classification or regression—the average or majority of those predictions result in a more accurate estimate.
The random forest algorithm, which makes use of both feature randomness and bagging to build an uncorrelated forest of decision trees, is thought of as an extension of the bagging method.
30. When should you use another algorithm over a random forest?
Despite being extremely quick to train, ensembles of decision trees (such as Random Forests, a name that has been registered for one specific implementation) take a long time to provide predictions after training.
The model must be used with more trees because more accurate ensembles require more trees. This method is quick in the majority of real circumstances, but there may be some where run-time performance is crucial and other methods are favored.
It is crucial to understand that this tool is for predictive modelling and not for descriptive purposes; if you need a description of the relationships in your data, you should explore other solutions.
Ensembles of decision trees are perhaps the most practical tool now available for quick, easy, adaptable predictive modeling, but like any method, they are not without flaws.