
DFS and BFS are elementary graph traversal algorithms. These algorithms form the heart of many other complex graph algorithms. Therefore, it is necessary to know how and where to use them.
We will go through the main differences between DFS and BFS along with the different applications. Following this, we will go through the basics of both the algorithms along with implementations.
Comparison of DFS and BFS
Following table highlights the difference between DFS and BFS:
| Basis | DFS | BFS |
|---|---|---|
| Traversal order | Depth | Level |
| Data structure Used | Stack | Queue |
| Time Complexity | O(V + E) | O(V + E) |
| Space Complexity | O(V) | O(V) |
| Traversal tree | Narrow and long | Wide and short |
- V is the number of vertices in the graph
- E is the number of edges in the graph
It is evident that both the algorithms are very similar when it comes to efficiency but the search strategy separates them from each other.
Although applications were mentioned spearately (further in this article) for each of them, many problems can be solved using either of them. For example, Kahn's algorithm uses BFS for finding the topological sort of a DAG whereas Bipartite checking can be done using DFS too.
Some applications of Depth First Search (DFS):
- Topological Sorting
- Kosaraju's algorithm or Tarjan's algorithm for strongly connected components
- Articulation points
Some applications of Breadth First Search (DFS):
- Bipartite Checking
- Shortest path and Garbage collection algorithms
The only lucid criteria for using BFS over DFS is when the path length (or level) used to explore a node has a significance. Example: In Web Crawler uses BFS to limit searching the web based on levels.
In almost every other case DFS is a great choice. DFS is also easier to implement as explicit usage of data structures can be avoided by recursive implementations.
DFS vs BFS example
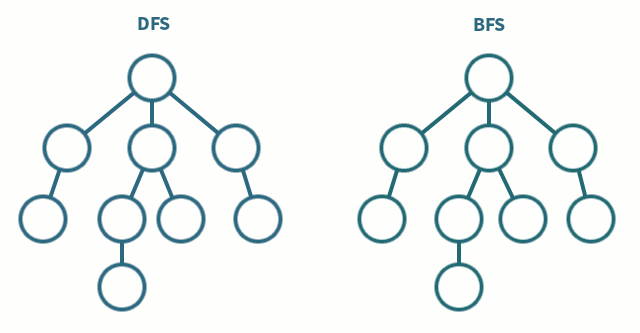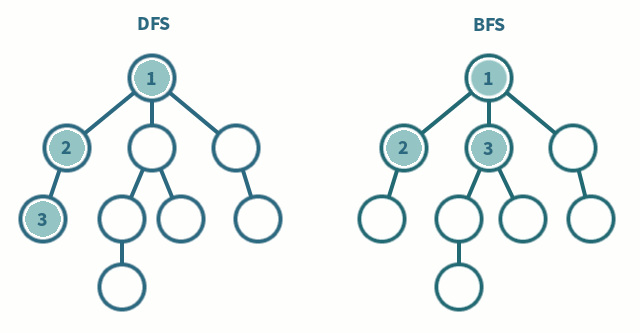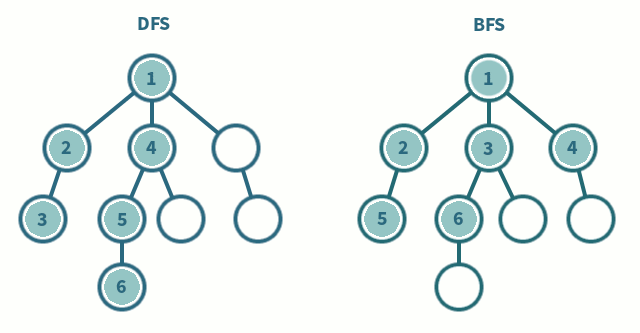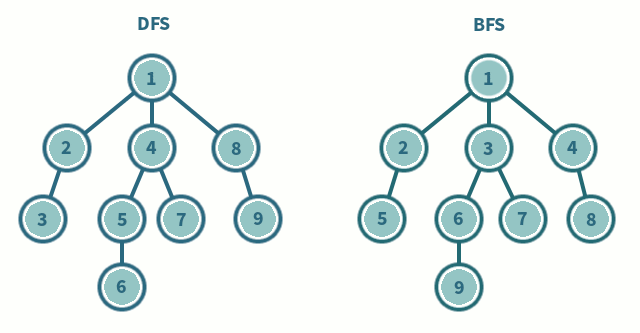
It can be seen in the above gif that DFS goes as deep as possible (no more new or unvisited vertices) and then backtracks. Whereas, BFS goes level by level, finishing one level completely before moving on to another level.
DEPTH FIRST SEARCH (DFS)
The strategy used by DFS is to go deeper in the graph whenever possible. It explores all the edges of a most recently discovered vertex u to the deepest possible point one at a time. After exploring all the edges of u, it backtracks to the vertex from which it arrived at u marking u as a visited vertex.
This search is naturally recursive in nature, therefore, it makes use of the stack data structure (Last In First Out). The explicit usage of stack can be avoided by using a recursive implementation, in which case the system stack is utilised.
The DFS traversal of a graph forms a tree, such a tree is called the DFS tree and it has many applications.
C++ Code
Note: graph is represented using adjacency list
void dfsVisit(vector<vector<int>>& graph,
vector<bool>& visited,
int u) {
visited[cur] = true;
// for all neighbours of u
for(auto v: graph[u]) {
if(visit[v] == false) {
dfsVisit(graph, visited, v);
}
}
}
void dfs(vector<vector<int>>& graph) {
int V = graph.size(); // number of nodes
vector<bool> visited(V + 1, false);
for(int u = 1; u <= V; ++u) {
if(visited[u] == false) {
dfsVisit(graph, visited, u);
}
}
}
The above code has two functions, the dfsVisit and dfs.
The dfsVisit function visits all reachable states of graph is Depth First order as mentioned above.
The dfs function iterates through all the nodes in the graph and for each unvisited node, it calls, the dfsVisit.
Complexity
The time complexity of DFS is O(V + E) where V is the number of vertices and E is the number of edges. This is because the algorithm explores each vertex and edge exactly once.
The space complexity of DFS is O(V). This is because in the worst case, the stack will be filled with all the vertices in the graph (Example: if the graph is a linear chain).
Applications
Topological Sorting
Topological Sorting is a linear ordering of veritces in a Directed Acyclic Graphs (DAGs), in this ordering, for every directed edge u to v, vertex u appears before vertex v. A single DFS routine is sufficient for performing a topological sort.
Strongly Connected Components (SCC)
SCCs of a directed graph G are subgraphs in which every vertex is reachable from every other vertex in the subgraph. One of the algorithms for finding SCCs is the Kosaraju's algorithm or Tarjan's algorithm, which is based on two DFS routines (One forward and one backward).
Articulation points and Bridges
Articulation points or Cut-vertices are those vertices of a graph whose removal disconnects the graph. Similarly, bridges are edges of a graph whose removal disconnects the graph. Both of them can be identified using the configuration of the DFS tree.
Breadth First Search (BFS)
The strategy used by BFS is to explore the graph level by level starting from a distinguished source node. Each level consists of a set of nodes which are equidistant from the source node. From a level L, all the unvisited nodes which are direct neighbours of the nodes in L are considered to be the next level, that is L+1.
This startegy explores the nodes based on their proximity to the source node, making it ideal for finding the shortest path from a source node to every other node in the graph.
To maintain the node's in level order, BFS uses queue datastructure (First In First Out).
Like DFS, BFS traversal ordering also results in a tree which is wide and short.
C++ code
Note: graph is represented using adjacency list
void bfs(vector<vector<int>>& graph,
int source) {
int V = graph.size();
vector<bool> visited(V + 1, false);
queue<int> que;
que.push(source);
visited[source] = true;
while(que.size()) {
int u = q.front(); q.pop();
for(auto v: graph[u]) {
if(visited[v] == false) {
visited[v] = true;
que.push(v);
}
}
}
}
The above code contains one function bfs. This function takes a graph and a source vertex as input and explores all the reachable states from source in a level order fashion.
At any state que contains nodes in non-decreasing order of their distance from the source node.
Complexity
The time complexity of DFS is O(V + E) where V is the number of vertices and E is the number of edges. This is because in the worst case, the algorithm explores each vertex and edge exactly once.
The space complexity of DFS is O(V) in the worst case. (Example: Star graph)
Applications
Shortest path
As mentioned previously, shortest path between any two nodes in an undirected graph can be found using BFS, assuming each edge is of equal length.
Bipartite checking
A Bipartite graph is one whose vertex set V can be separated into two sets V1 and V2, such that every vertex belongs to exactly one of them and the end vertices of every edge u, v belong to different sets. BFS can be used to find whether a graph is bipartite or not. This is done by checking if it's possible to color the graph using exactly two colors.
Garbage collection
Garbage collection is a form of automatic memory management where unused memory is reclaimed by clearing them. Cheney's algorithm using BFS to accomplish this.
Question
In social network graphs, there's a requirement of finding all contacts who are at a given distance k from a person. What is the most suitable algorithm that can be used to find such contacts?
Question
What is the most suitable algorithm to find the number of connected components in a graph?
With this article at OpenGenus, you must have the complete idea of differences between Breadth First Search (BFS) and Depth First Search (DFS). Enjoy.