
Scrapping Information is used to extract useful information from YouTube videos. Sometimes, we need to write the content from the youtube videos directly but cannot. This article will help you achieve to create functionality for scrapping information from the videos at YouTube using Puppeteer and Cheerio.
With the help of Scrapping information we can:
- Find out who among the several people are stealing your information.
- Getting liked and famous using a specific keyword.
- Using what kind of strategies to achieve success.
- Can be used in content creation.
We will achieve the task with help of a node library called Puppeteer and cheerio. First let us learn about Puppeteer.
Puppeteer
Puppeteer is a library for Node.js which provides a high-level API to control Chrome over the DevTools Protocol.
Features of using Puppeteer ->
- It generates screenshots and PDFs of pages.
- Crawl Single-Page Applications
- Generate pre-rendered content.
- Automate form submission, UI testing, keyboard input, etc.
- Create an up-to-date, automated testing environment.
- Capture a timeline trace of your site to help diagnose performance issues.
- Test Chrome Extensions.
Cheerio
Cheerio parses markup and gives an API for navigating or controlling the resulting data structure. It doesn't interpret the outcome as a web browser does. In particular, it doesn't create a visual rendering, apply CSS, load outside assets, or execute JavaScript.
Features of cheerio
-
User-Friendly syntax: Cheerio executes in a very familiar syntax making it an efficient API.
-
Fast Performance: Performance in Cheerio is very fast since it works with an very basic and consistent DOM model.
-
Flexible to use: Due to its Familiar syntax and fast performance, Cheerio is very flexible to use.
Getting Started
We are going to develop this tool with the help of node.js and puppeteer.
So, lets get started ->
- First, Lets make a project directory ->
mkdir scraping
cd scraping
- Now, initialize the project with package.json file ->
npm init
After executing the above given code, the output will be ->
{
"name": "scrapping-information-from-youtube-master",
"version": "1.0.0",
"description":"",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC"
}
- Installing puppeteer and cheerio
npm install puppeteer cheerio
- Our package.json will look like ->
{
"name": "scrapping-information-from-youtube-master",
"version": "1.0.0",
"description": "",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "",
"license": "ISC",
"dependencies": {
"cheerio": "^1.0.0-rc.3",
"puppeteer": "^2.1.1"
}
}
Developing the Application
Now, that the libraries needed are installed, firstly, we will create a file named "scrapping.js" to enable us to scrap information from youtube.
Here is the code for scrapping.js ->
const cheerio = require('cheerio');
module.exports = {
scrape_info: scrape_info,
};
Here, we are importing the library called "cheerio" in our program. In the next line, we used exports property for the program to be used by other applcations
... //Here is the lines of code written above
const videos = new Set();
const sleep = seconds =>
new Promise(resolve => setTimeout(resolve, (seconds || 1) * 1000));
Here, the "new" keyword is used to create an instance of a user-defined object type. It does the following ->
- Links object of the current class to the another object.
- Passes the newly created object as "this".
- Returns "this" if the function doesn't return its own object.
Next, we used Promise keyword here. A promise can be created using Promise constructor. They are used to handle asynchronous requests or operations. Promises makes it easy to deal with multiple asynchronous operations. It improves the code and provides better error handling.
Promise has four stages -> - fulfilled - Operations related to promise are fulfilled.
- rejected - Operations related to promise failed.
- pending - Operations related to promise are still pending.
- settled - Operations related to promise are either fulfilled or rejected.
...
async function scrape_info(browser, keywords) {
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
await page.goto('https://www.youtube.com');
Here, async/await is a special syntax to work with promises. We use the word "async" before a function that simple means - the function must always return a promise.
Now, the "await" keyword makes the javascript wait until the promise settles and returns its result.
In the scrap_info() function, we customized the page size by page.setViewport and passing the size as arguments. the default page size is 800x600 px. And, finally it redirects to "youtube.com" using page.goto() function.
...
try {
await page.waitForSelector('input[id="search"]', { timeout: 5000 });
} catch (e) {
return results;
}
Here, .waitForSelector() is used for hanging the page till the time provided in the timeout but not ending it.
...
const results = {};
await page.waitForSelector('ytd-video-renderer,ytd-grid-video-renderer', { timeout: 10000 });
let html = await page.content();
results['__frontpage__'] = parse(html);
for (var i = 0; i < keywords.length; i++) {
keyword = keywords[i];
try {
const input = await page.$('input[id="search"]');
await input.click({ clickCount: 3 });
await input.type(keyword);
await input.focus();
await page.keyboard.press("Enter");
await page.waitForFunction(`document.title.indexOf('${keyword}') !== -1`, { timeout: 5000 });
await page.waitForSelector('ytd-video-renderer,ytd-grid-video-renderer', { timeout: 5000 });
await sleep(1);
let html = await page.content();
results[keyword] = parse(html);
} catch (e) {
console.error(`Problem with scraping ${keyword}: ${e}`);
}
}
return results;
}
Here, page.content() gets the full HTML contents of the page, including the doctype. We store the contents of the HTML of the page in the variable named as "html". Later in the code the HTML contents of the page is parsed.
In the try block, we overwrite the last text we provided in input.
Here, the sleep() function is used with async to continue with the proceedings. Sleep() function pauses the function for the given time in the argument.
...
function parse(html) {
const $ = cheerio.load(html);
Here the .load() function loads the data from the HTML content and will store the returned data into the variable.
...
const results = [];
$('#contents ytd-video-renderer,#contents ytd-grid-video-renderer').each((i, link) => {
results.push({
link: $(link).find('#video-title').attr('href'),
title: $(link).find('#video-title').text(),
snippet: $(link).find('#description-text').text(),
channel: $(link).find('#byline a').text(),
channel_link: $(link).find('#byline a').attr('href'),
num_views: $(link).find('#metadata-line span:nth-child(1)').text(),
release_date: $(link).find('#metadata-line span:nth-child(2)').text(),
})
});
const cleaned = [];
for (var i=0; i < results.length; i++) {
let res = results[i];
if (res.link && res.link.trim() && res.title && res.title.trim()) {
res.title = res.title.trim();
res.snippet = res.snippet.trim();
res.rank = i+1;
Here, we created an empty array for results and later in the code we push the array with the elements like - link, channel, title, snippet, etc.
...
if (videos.has(res.title) === false) {
cleaned.push(res);
}
videos.add(res.title);
}
}
return {
time: (new Date()).toUTCString(),
results: cleaned,
}
}
Here, The starting lines of code functions to check if the result has been already used before or not.
The Final code for "scrapping.js" looks like ->
const cheerio = require('cheerio');
module.exports = {
scrape_info: scrape_info,
};
const videos = new Set();
const sleep = seconds =>
new Promise(resolve => setTimeout(resolve, (seconds || 1) * 1000));
async function scrape_info(browser, keywords) {
const page = await browser.newPage();
await page.setViewport({ width: 1280, height: 800 });
await page.goto('https://www.youtube.com');
try {
await page.waitForSelector('input[id="search"]', { timeout: 5000 });
} catch (e) {
return results;
}
const results = {};
await page.waitForSelector('ytd-video-renderer,ytd-grid-video-renderer', { timeout: 10000 });
let html = await page.content();
results['__frontpage__'] = parse(html);
for (var i = 0; i < keywords.length; i++) {
keyword = keywords[i];
try {
const input = await page.$('input[id="search"]');
await input.click({ clickCount: 3 });
await input.type(keyword);
await input.focus();
await page.keyboard.press("Enter");
await page.waitForFunction(`document.title.indexOf('${keyword}') !== -1`, { timeout: 5000 });
await page.waitForSelector('ytd-video-renderer,ytd-grid-video-renderer', { timeout: 5000 });
await sleep(1);
let html = await page.content();
results[keyword] = parse(html);
} catch (e) {
console.error(`Problem with scraping ${keyword}: ${e}`);
}
}
return results;
}
function parse(html) {
const $ = cheerio.load(html);
const results = [];
$('#contents ytd-video-renderer,#contents ytd-grid-video-renderer').each((i, link) => {
results.push({
link: $(link).find('#video-title').attr('href'),
title: $(link).find('#video-title').text(),
snippet: $(link).find('#description-text').text(),
channel: $(link).find('#byline a').text(),
channel_link: $(link).find('#byline a').attr('href'),
num_views: $(link).find('#metadata-line span:nth-child(1)').text(),
release_date: $(link).find('#metadata-line span:nth-child(2)').text(),
})
});
const cleaned = [];
for (var i=0; i < results.length; i++) {
let res = results[i];
if (res.link && res.link.trim() && res.title && res.title.trim()) {
res.title = res.title.trim();
res.snippet = res.snippet.trim();
res.rank = i+1;
if (videos.has(res.title) === false) {
cleaned.push(res);
}
videos.add(res.title);
}
}
return {
time: (new Date()).toUTCString(),
results: cleaned,
}
}
Let us take an example of what the results array of our code will store. Suppose we want to scrap information from a youtube video, then the output of results array in console will be -> In this example, suppose we want to scrap from video link - https://www.youtube.com/watch?v=z_mzJnk31Cg at 344sec(5.44min)
[
link: 'https://www.youtube.com/watch?v=z_mzJnk31Cg&t=344s',
title: '100 Days Of Code - The Rules #100DaysOfCode',
snippet: 'In this video, I am going over the rules of the #100DaysOfCode challenge.',
channel: 'Do The Opposite',
channel-link: 'https://www.youtube.com/channel/UCRbVkIsLLwrKuZrPhyJ4xaw',
num_views: '19487',
release_date: 'July 7, 2016'
]
We can see the screenshot of the page used in example ->
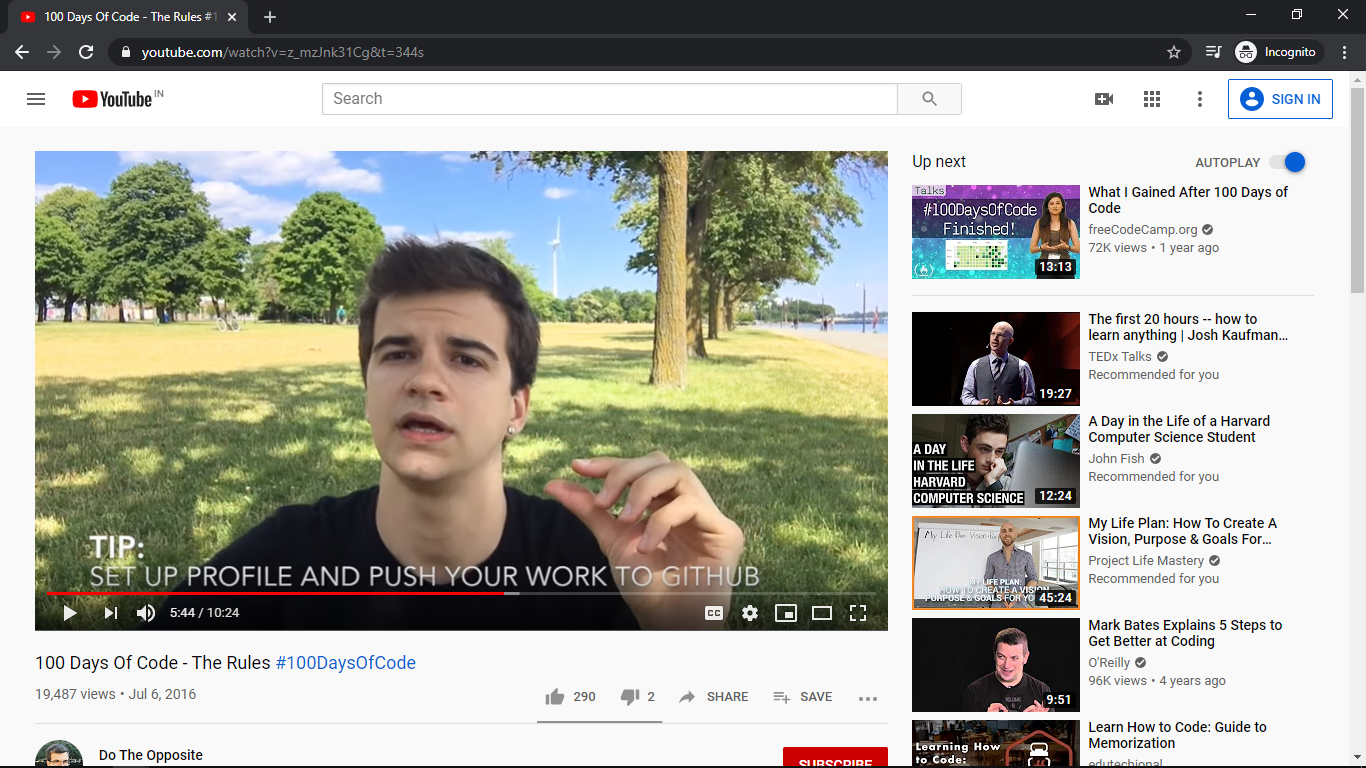
Using the library in applications to scrap information
Now, we will use the library "scrapping.js" in other application and scrap informations.
Create a file named "index.js". Here is the code for "index.js"
const puppeteer = require('puppeteer');
const scrapping = require('./scrapping');
Here, we are importing the two library needed for our application named as puppeteer and scrapping(the application we developed above).
...
try {
(async () => {
let keywords = [
'OpenGenus',
'Software Developer',
'Work from Home',
'author',
'developer',
];
const browser = await puppeteer.launch();
let results = await scrapping.scrape_info(browser, keywords);
console.dir(results, {depth: null, colors: true});
await browser.close();
})()
} catch (err) {
console.error(err)
}
Here, we can enter any keyword in "keywords" array that we want to search in youtube videos.
The function scrap_info() is called and the results are returned according to the keywords provided.
The complete code for "index.js" looks like this ->
const puppeteer = require('puppeteer');
const scrapping = require('./scrapping');
try {
(async () => {
let keywords = [
'OpenGenus',
'Software Developer',
'Work from Home',
'author',
'developer',
];
const browser = await puppeteer.launch();
let results = await scrapping.scrape_info(browser, keywords);
console.dir(results, {depth: null, colors: true});
await browser.close();
})()
} catch (err) {
console.error(err)
}
After completing the coding process, its time to run the application. To run the application, run the following command ->
node index.js
After running the command, the output will look like this ->
Therefore, with this article at OpenGenus, we have completed the development of an application that is used to scrap information from youtube videos using some keywords.