
Get this book -> Problems on Array: For Interviews and Competitive Programming
Hello everybody, today we will discuss one of the revolutionary concepts in the artificial intelligence sector not only in Natural Language Processing but also nowadays in the Computer Vision, which is the Transformers and the heart of it Self-Attention.
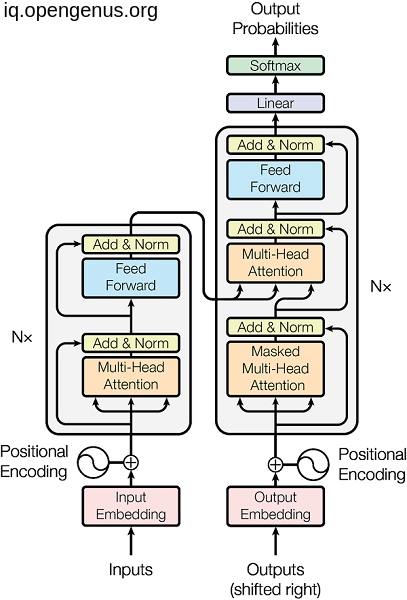
Table of Contents :
1. Before transformers.
2. Attention is all you need.
3. Self-Attention.
4. Multi head attention.
5. Multiple encoder and decoder.
6. attention vs self-attention vs multi-head attention.
7. Application.
In our journey today we are trying to discuss the self attention of transformers of machine translator model which the original paper Attention is all you need suggest.
1. Before transformers :
We know that there was a problem in the RNN model with Fixed-size context vector (encoder-decoder based RNN) So this context vector can't store all relevant information with larger size inputs.
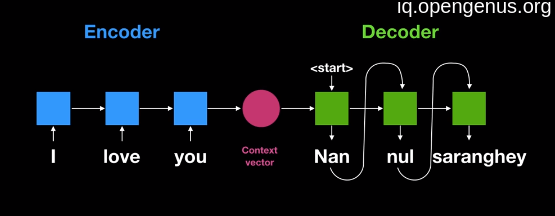
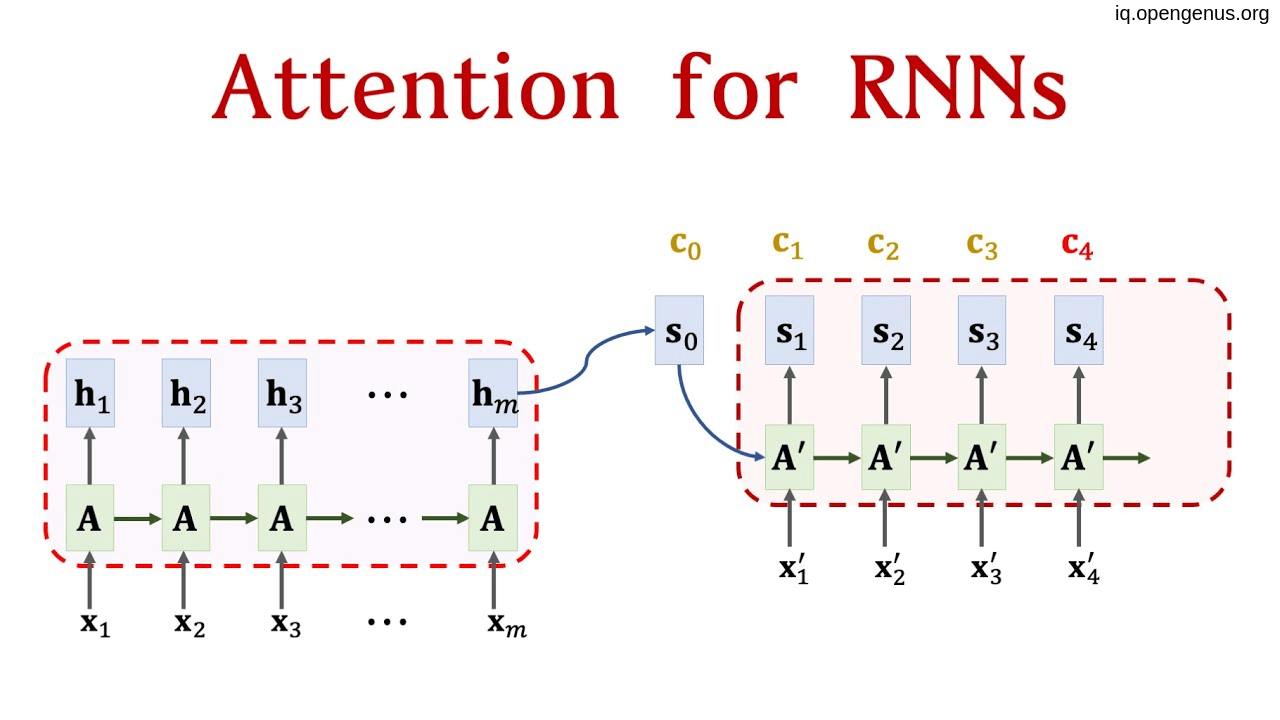
So, in order to overcome this problem we start using RNN based encoder-decoder with Attention and fortunately this give us the desired result of ability to reserve all possible information of highly large inputs.
But due to RNN this approach still slow and performance is not perfect.
2. Attention is all you need:
In 2017 a paper called Attention is all you need Suggest that we can get rid of RNN cells and only need attention and build a new encoder-decoder based architecture called transformers and As we all know this paper and this approach since this time and it only made a revolution in the AI field. So, what is attention and what is its mechanism?
3. Self-Attention:
SO, we can highlight the self attention mechanism as it is a process that trying to make each single input to pay attention to the other inputs in the same sequence. this attention is weighted to each other input and this weight is trainable. So it take an input N and produce an output N that contain more information regarding to the same input sequence as we will see.
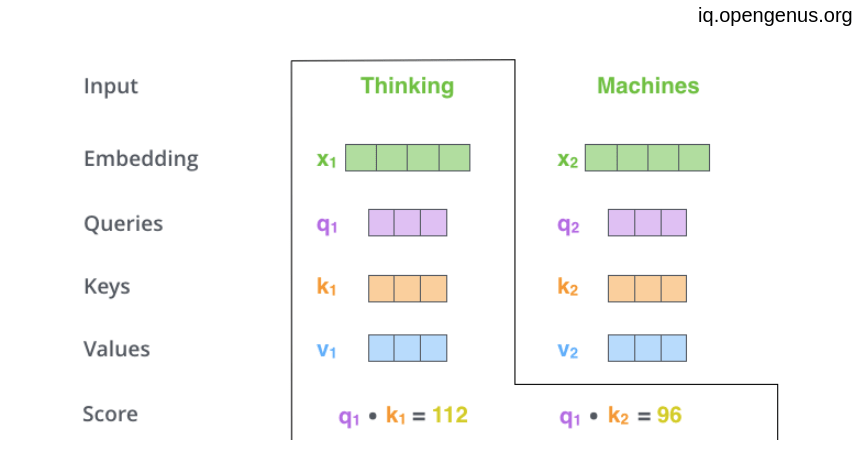
The first step is to try to get a Query vector, a Key vector, and a Value vector associating to each word by multiplying the word embedding by Query matrix, a Key matrix, and a Value matrix that will be trained during the training process.
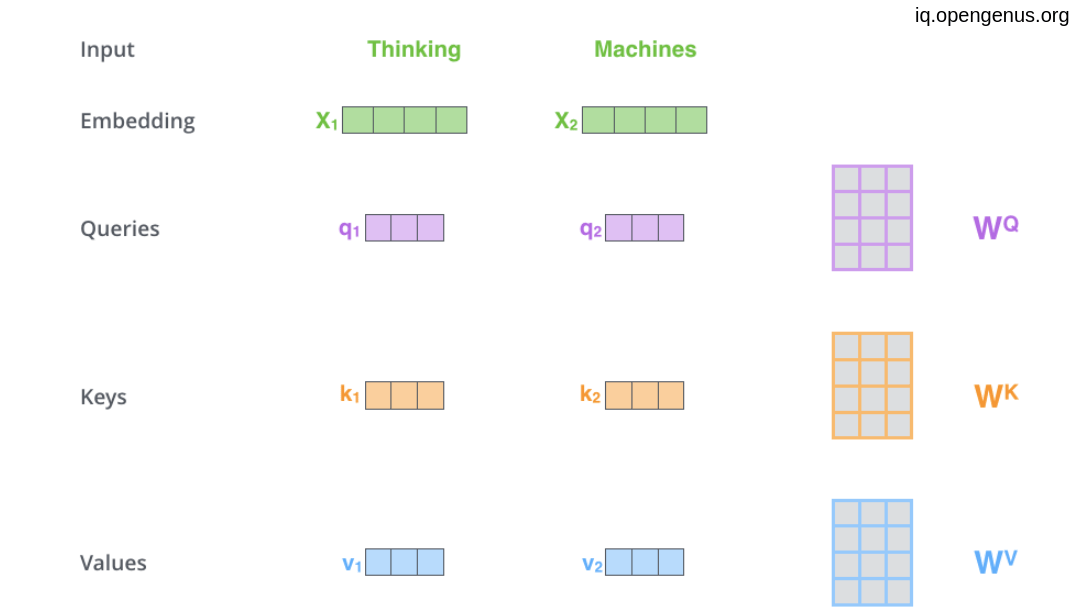
Then we need to calculate The Score by which each word will give to the other words .
The score is calculated as the dot product of query vector with the transpose of key vector of the respective word we are scoring against.
So, the score that first word give to itself will be q1.k1T
then according to the paper we do a scaling layer by dividing by the square root of the dimension of the key vectors(64 in the paper) and this in order to get more stable gradients, then taking the softmax score or normalization process so that all scores are sum up to one.
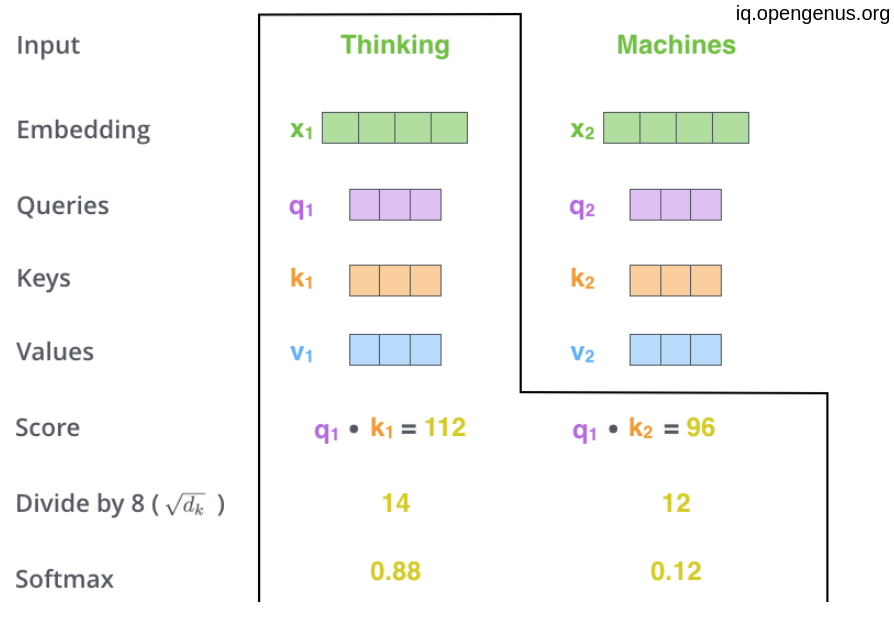
the result determines how much each world we be represented at that position.
And finally multiplying the result with the value vector of each word then add the up and the result is the self attention for the first position.

And by the same technique we can calculate the self attention layer at each position in Parallel which save a lot of time and effort.

4. Multi head attention:
All we discussed above is only one attention block but we can use the great parallelization for multi head attention where we can stack more than one attention block above each others (the paper suggest 8) the concatenate the outputs and multiplying the result with another matrix that also will train with the model.
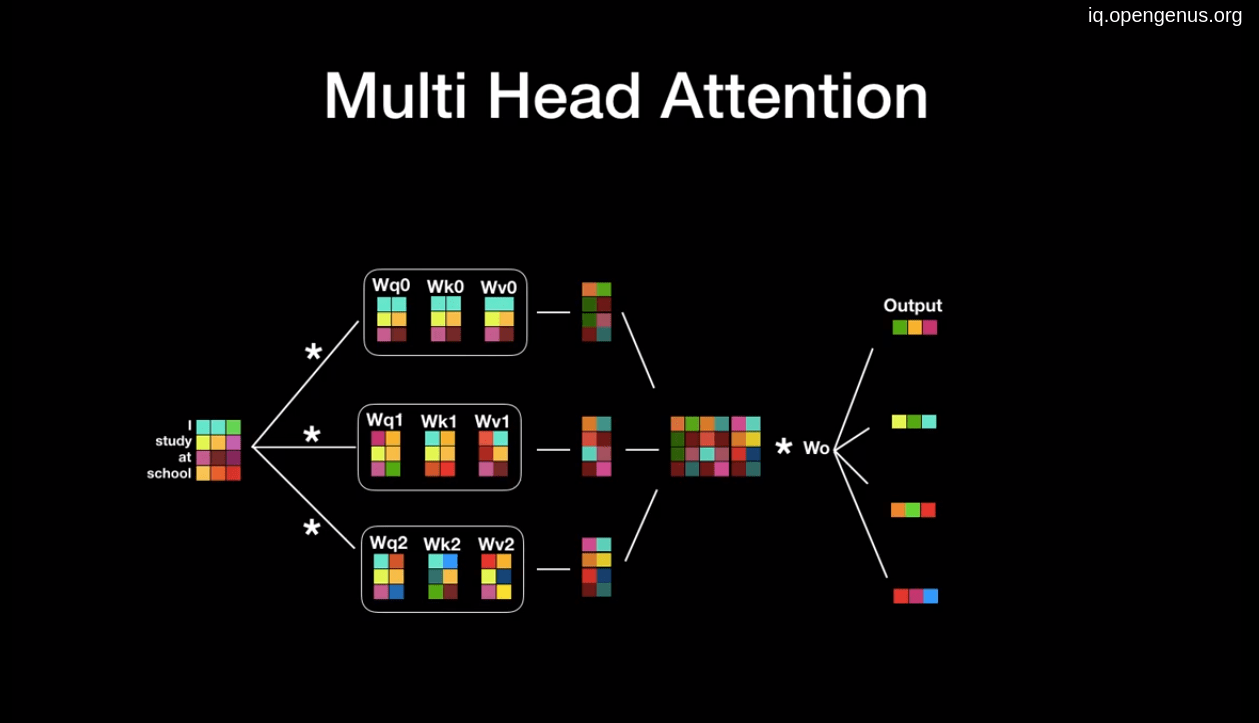
5. Multiple encoder and decoder:
Not only the the attention heads that we can stack but also the encoder and the decoder themselves. this is obvious in the below image as (Nx).
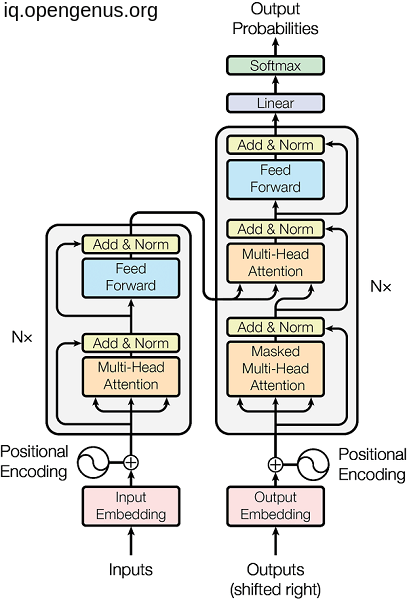 .
.
And it is not obligatory to use the both encoder and decoder architecture as we will see in a second.
6. attention vs self-attention vs multi-head attention
| Attention | Self-Attention | Multi-head Attention | |
|---|---|---|---|
| Description | the ability of a transformer to attend to different parts of "another sequence" when predict | the ability of a transformer to attend to different parts of the same input sequence when predict. | Using advantage of parallelization to make more than one head of attention mechanism |
| Application | applied to transfer information from encoder to decoder | applied within one component | Usually used with self-attention |
| can connect two different blocks | can't connect two different blocks | ||
| applied once in the model when connects some 2 components | can be applied many times within a single model | ||
| can be used for different modalities (images and text) | usually applied within a single modality(text or images) |
7. Application:
- Transformers that based on the encoder side --> BERT used in NLP tasks such as sentiment classification
- Transformers that based on the decoder side --> GPT-2 and GPT-3 specially chatGPT-3 which consider nowadays a miracle in NLP as it can do many tasks like classification, answer questions, data analysis and even write an article or assist in it.
- Transformers that use the encoder and decoder sides --> BART used in several NLP tasks such as text classification, text generation, text summarization, and question answering.
And Finally I want to thank you for accompanying me in this journey.